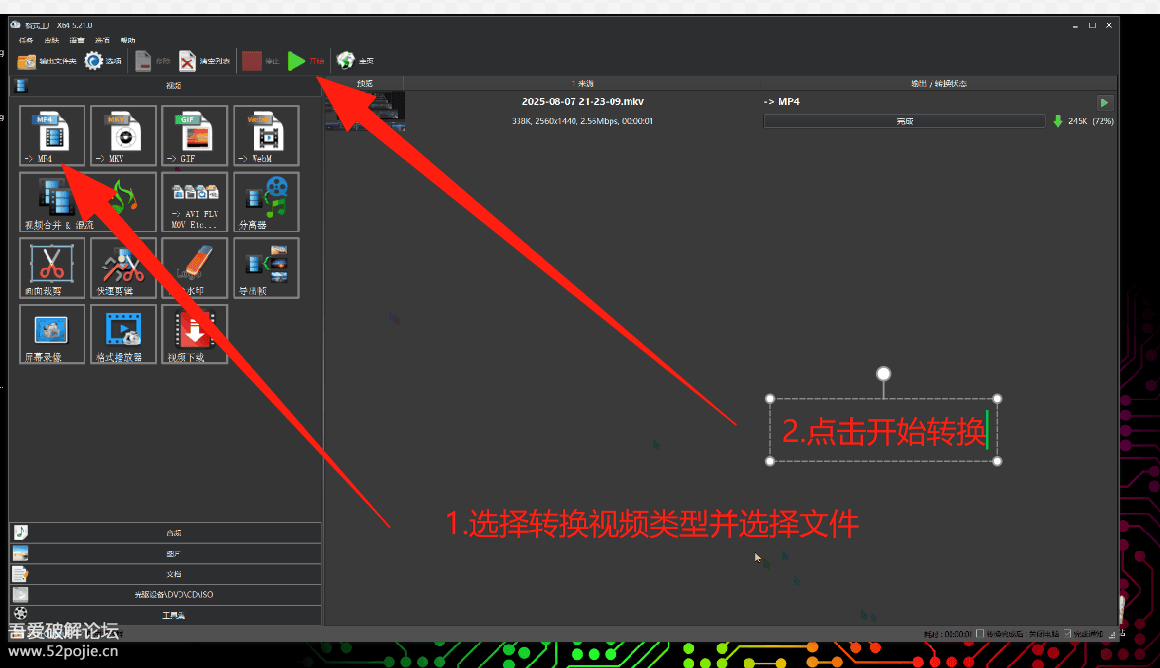
HTTP的Transfer-Encoding在爬虫中有何影响?HTTP的Transfer-Encoding对爬虫有多方面的影响: 1. 分块传输(chunked)处理:爬虫需要正确解析分块编码的响应,否则可能导致数据解析错误。分块传输允许爬虫流式处理数据,而不必将整个响应加载到内存中,提高大文件处理效率。 2. 压缩编码处理:当Transfer-Encoding包含gzip、deflate等压缩算法时,爬虫需要解压数据才能获取原始内容。虽然压缩减少了网络传输量,但会增加CPU解压开销。 3. 性能优化:分块传输使爬虫可以提前开始处理部分数据而不必等待完整响应,特别适合处理大文件或流式数据。 4. 内存使用:正确处理Transfer-Encoding尤其是分块传输,可以显著降低爬虫的内存使用,避免因大响应导致的内存溢出。 5. 错误处理:爬虫需要能够处理Transfer-Encoding与Content-Encoding的组合情况,以及各种编码解析错误,避免数据损坏。 6. 协议兼容性:现代爬虫需要同时支持HTTP/1.1(使用Transfer-Encoding)和HTTP/2(不使用Transfer-Encoding),需注意协议差异。 如何在爬虫中实现 HTTP 的 PATCH 请求?在爬虫中实现HTTP PATCH请求主要有以下几种方法: 1. 使用Python的requests库(最常用): 复制代码 隐藏代码
import requests
url = 'https://example.com/api/resource'
data = {'key': 'new_value'} # 要更新的数据
headers = {'Content-Type': 'application/json'} # 根据API要求设置适当的headers
response = requests.patch(url, json=data, headers=headers)
print(response.status_code)
print(response.json())2. 如果需要发送表单数据而不是JSON: 复制代码 隐藏代码
response = requests.patch(url, data=data, headers=headers)3. 使用urllib库实现: 复制代码 隐藏代码
from urllib.request import Request, urlopen
import json
url = 'https://example.com/api/resource'
data = {'key': 'new_value'}
data = json.dumps(data).encode('utf-8')
headers = {'Content-Type': 'application/json'}
request = Request(url, data=data, method='PATCH', headers=headers)
response = urlopen(request)
print(response.status)
print(response.read().decode('utf-8'))注意事项: • 确保目标API支持PATCH请求 • 检查API文档,了解正确的请求格式和headers • 处理可能的认证,如API密钥、OAuth等 • 添加适当的错误处理代码 HTTP 的 Link 头在爬虫链接发现中有何用途?HTTP的Link头在爬虫链接发现中有多种重要用途:1) 分页处理,提供下一页、上一页等导航链接;2) 发现相关资源,如作者信息、相关文章等;3) API版本控制,指向不同版本的API资源;4) 搜索结果导航,提供过滤、排序等参数链接;5) 预加载提示,提高抓取效率;6) 资源关系描述,通过rel属性说明资源间语义联系;7) 提供替代格式,指向同一资源的不同格式版本;8) 实现HATEOAS原则,动态提供可执行的操作链接。Link头使爬虫能够更智能地导航和发现内容,特别是在现代Web API和RESTful服务中。 如何在爬虫中处理 HTTP 的 429 Too Many Requests?处理HTTP 429 Too Many Requests错误的方法包括:1) 实现速率限制,添加请求延迟或使用指数退避算法;2) 解析响应头中的Retry-After字段,按建议等待时间重试;3) 使用代理IP轮换分散请求;4) 实现请求队列控制发送速率;5) 遵守robots.txt规则;6) 使用Scrapy等框架内置的限速功能;7) 添加随机延迟模拟人类行为;8) 设置合理的重试机制;9) 轮换User-Agent避免识别;10) 监控请求日志分析模式。 HTTP 的 Retry-After 头如何指导爬虫重试?HTTP的Retry-After头用于告知爬虫应该在多长时间后重试请求。它通常出现在429(Too Many Requests)或503(Service Unavailable)响应中,包含两种可能的值:1)相对秒数(如120表示120秒后重试);2)绝对时间(如'Wed, 21 Oct 2015 07:28:00 GMT'表示具体时间点)。爬虫应当严格遵守这个延迟时间,在等待期间不向该服务器发送新请求或大幅降低请求频率。这种机制帮助爬虫避免被服务器封禁IP,减轻服务器负载,并体现尊重目标网站资源的行为准则。 如何在爬虫中处理 HTTP 的 502 Bad Gateway?处理爬虫中的502 Bad Gateway错误可以采取以下策略:1) 实现重试机制,使用指数退避策略并设置合理的重试次数;2) 控制请求频率,避免短时间内大量请求;3) 使用代理IP池,在出现502时切换代理;4) 记录错误日志并分析错误模式;5) 设置合理的请求头,包括User-Agent等;6) 实现熔断机制,连续出现502时暂停请求;7) 准备备用数据源;8) 使用分布式爬虫分散请求;9) 遵守robots.txt规则;10) 使用成熟的爬虫框架如Scrapy,它们通常内置了错误处理机制。 HTTP的Content-Type头在爬虫数据解析中有何作用?HTTP的Content-Type头在爬虫数据解析中起着关键作用:1)指定响应数据的格式(HTML、JSON、XML等),帮助爬虫选择正确的解析方法;2)提供字符编码信息(charset),确保正确处理非英文文本,避免乱码;3)帮助爬虫识别并处理不同类型的数据;4)防止错误解析,如将JSON误认为HTML;5)处理没有明确Content-Type的特殊情况;6)增强安全性,防止将响应内容误作为可执行代码处理;7)提高爬虫健壮性,处理服务器返回错误页面但状态码为200的情况。 如何在爬虫中实现 HTTP 的 HEAD 请求?在爬虫中实现 HTTP 的 HEAD 请求可以使用多种编程语言和库: 1. Python 使用 requests 库: 复制代码 隐藏代码
import requests
url = "https://example.com"
response = requests.head(url)
print(response.status_code) # 查看响应状态码
print(response.headers) # 查看响应头2. Python 使用 urllib 库: 复制代码 隐藏代码
from urllib.request import Request, urlopen
url = "https://example.com"
req = Request(url, method='HEAD')
response = urlopen(req)
print(response.status) # 查看响应状态码
print(response.headers) # 查看响应头3. Node.js 使用 axios: 复制代码 隐藏代码
const axios = require('axios');
axios.head('https://example.com')
.then(response => {
console.log('Status:', response.status);
console.log('Headers:', response.headers);
});HEAD 请求只获取资源的头部信息而不返回内容体,适用于检查资源是否存在、获取元数据或检查资源是否被修改。 HTTP 的 Accept-Language 头在爬虫本地化中有何用途?HTTP的Accept-Language头在爬虫本地化中有多项重要用途:1) 获取特定语言版本的内容,而不是默认语言;2) 模拟来自不同地区的用户访问,获取本地化内容;3) 绕过基于IP或浏览器的语言重定向,直接请求特定语言版本;4) 分析网站的多语言SEO策略,如检查hreflang标签实现;5) 对比同一网站在不同语言下的内容差异;6) 评估自动翻译质量;7) 尊重网站的语言偏好设置,提高爬取相关性和减少被封禁风险。通过设置合适的Accept-Language头,爬虫可以更精准地获取本地化信息,提升数据采集的针对性和质量。 如何在爬虫中处理 HTTP 的 406 Not Acceptable?处理HTTP 406 Not Acceptable错误的主要方法包括:1) 修改请求头中的Accept字段,使其更通用或删除特定要求;2) 添加或修改User-Agent模拟浏览器;3) 添加适当的请求延迟;4. 使用会话管理(requests.Session);5. 考虑使用代理IP;6. 完善其他请求头如Accept-Language、Accept-Encoding等;7. 对于需要JavaScript渲染的网站,使用Selenium等工具;8. 遵守robots.txt规定。示例代码:使用requests库时,可以捕获406错误,然后修改请求头重试;使用Scrapy时,可以在中间件中处理406状态码,修改请求头后重试。 HTTP 的 Content-Disposition 头在爬虫文件下载中有何作用?在爬虫文件下载中,Content-Disposition 头主要有以下作用:1) 提供服务器推荐的文件名(通过 filename 参数),使爬虫能以原始名称保存文件;2) 指示响应类型(inline 或 attachment),帮助爬虫确定是否需要下载;3) 处理特殊字符和编码(如 filename* 参数);4) 避免文件名冲突,特别是当 URL 不包含有意义的名称时;5) 支持内容协商,获取更适合的文件格式。爬虫通常解析此头以获取正确的文件名和下载行为指示。 如何在爬虫中处理 HTTP 的 400 Bad Request?处理 HTTP 400 Bad Request 错误的几种方法: 1. 检查请求参数: • 验证所有必需参数是否已提供 • 检查参数格式是否正确(如日期格式、ID格式等) • 确认参数值在有效范围内 2. 完善请求头: • 设置合适的 User-Agent • 添加必要的 Referer 头 • 确保 Content-Type 正确(特别是 POST 请求) 3. 处理编码问题: • 确保请求数据编码正确(UTF-8 通常是最安全的选择) • 检查 URL 参数是否正确编码 4. 实现重试机制: • 使用指数退避算法重试失败的请求 • 设置最大重试次数避免无限循环 5. 模拟浏览器行为: • 添加必要的 cookies • 处理会话和认证信息 • 遵循 robots.txt 规则 6. 错误日志记录: • 记录详细的错误信息以便分析 • 记录请求参数和响应内容 7. 使用工具辅助: • 使用开发者工具查看浏览器实际发送的请求 • 对比正常请求与爬虫请求的差异 HTTP 的 Accept-Charset 头在爬虫编码处理中有何用途?HTTP的Accept-Charset头在爬虫编码处理中有多方面用途:1) 编码协商:爬虫通过此头告诉服务器它接受的字符编码,使服务器返回适当编码的内容;2) 提高效率:减少因编码不匹配导致的解析错误和额外处理;3) 多语言支持:表示支持多种字符编码(如UTF-8、GBK等),便于处理多语言内容;4) 防止乱码:明确指定接受的编码减少乱码可能性;5) 与Content-Type头配合:服务器可根据此信息返回适当编码并在Content-Type中指定实际编码;6) 编码检测备选:即使服务器返回编码不匹配,可作为备选方案尝试;7) 处理老旧网站:包含多种编码提高兼容性。虽然现代Web普遍使用UTF-8,但在处理特定区域内容或老旧系统时仍很有价值。 如何在爬虫中处理 HTTP 的 409 Conflict?处理HTTP 409 Conflict(冲突)状态码的方法: 1. 实现重试机制:使用带有指数退避的重试策略,避免立即重试导致服务器负担 2. 解析响应内容:检查响应体中的错误详情,了解具体冲突原因(如资源已存在、版本冲突等) 3. 使用条件请求:添加If-Match、If-None-Match或If-Unmodified-Since等条件请求头 4. 修改请求策略:根据冲突原因调整请求参数,如修改数据、改变请求时间等 5. 处理并发冲突:对于多线程爬虫,实现请求队列和适当的锁机制 6. 实现退避策略:遇到409错误时,随机或按比例增加等待时间再重试 7. 记录冲突情况:记录冲突URL和原因,便于后续分析优化爬虫策略 HTTP 的 X-Frame-Options 头如何影响爬虫?X-Frame-Options 头主要设计用于防止点击劫持攻击,对爬虫的影响相对有限:1) 它限制页面在 iframe/框架中的显示,但不直接阻止内容获取;2) 大多数现代爬虫直接获取HTML源码而非依赖框架渲染,因此通常不受影响;3) 依赖JavaScript在iframe中加载内容的爬虫可能会受到限制;4) 它不是专门的反爬虫机制,而是网站安全策略的一部分;5) 当与其他反爬虫头部配合使用时,可能增强反爬效果。总体而言,X-Frame-Options对专业爬虫的阻挡作用有限。 如何在爬虫中处理 HTTP 的 504 Gateway Timeout?处理HTTP 504 Gateway Timeout错误可以采取以下策略: 1. 实现重试机制: • 使用指数退避算法进行重试(如第一次重试等待1秒,第二次等待2秒,第三次等待4秒等) • 设置合理的最大重试次数(通常3-5次) 2. 调整请求参数: • 增加请求超时时间 • 使用连接池复用连接 3. 使用代理IP轮换: • 当频繁出现504错误时,切换代理IP • 使用代理IP池进行轮换 4. 请求频率控制: • 实现请求间隔,避免过于频繁的请求 • 使用随机延迟模拟人类行为 5. 分布式爬虫: • 将爬取任务分散到多个节点 • 使用分布式框架如Scrapy-Redis 6. 代码实现示例(Python requests): 复制代码 隐藏代码
import time
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
defget_session_with_retry():
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[504, 502, 503, 408]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
return session
deffetch_url(url, timeout=30):
session = get_session_with_retry()
try:
response = session.get(url, timeout=timeout)
response.raise_for_status()
return response
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None7. 预防措施: • 遵守robots.txt规则 • 使用随机User-Agent • 实现请求限速 • 监控目标网站状态 HTTP 的 Content-MD5 头在爬虫数据验证中有何用途?Content-MD5 头在爬虫数据验证中主要有以下用途:1) 数据完整性验证,爬虫可以通过比较接收到的数据的MD5值与服务器提供的Content-MD5值,确认数据在传输过程中未被篡改或损坏;2) 内容变化检测,通过比较同一URL不同时间爬取的Content-MD5值,判断内容是否发生变化;3) 缓存优化,当MD5值与缓存中的一致时,可直接使用缓存数据,减少重复下载;4) 避免重复爬取,记录已爬取内容的MD5值,防止爬取相同内容;5) 在分布式爬虫系统中,确保不同节点获取到相同内容。需要注意的是,MD5算法已存在安全局限,在安全性要求高的场景建议使用更安全的哈希算法或依赖TLS机制。 TCP 的三次握手和四次挥手过程对爬虫有何影响?TCP的三次握手和四次挥手过程对爬虫有多方面的影响: 1. 延迟增加:每次请求都需要三次握手,这会增加请求的延迟,影响爬取效率。爬虫通常需要快速获取大量数据,而握手过程会消耗时间。 2. 资源消耗:频繁的握手和挥手会消耗大量系统资源(CPU、内存、端口资源),对于大规模爬虫来说,这种消耗更为显著。 3. 连接管理:爬虫需要实现连接复用机制(如HTTP Keep-Alive)和连接池,以减少握手次数。同时要处理TIME_WAIT状态,避免端口耗尽问题。 4. 反爬虫限制:频繁的连接建立和断开可能被服务器识别为异常行为,触发反爬机制,导致IP被封禁或请求被限制。 5. 代理IP使用:使用代理时,每次切换代理都需要重新建立连接,增加握手次数和延迟,影响爬取效率。 6. 超时处理:爬虫需要正确处理握手超时、连接失败等异常情况,确保爬取任务的稳定性和可靠性。 7. 性能优化:现代爬虫框架通常会实现连接复用、异步请求、域名分片等技术,以减少TCP握手带来的性能影响。 TCP的滑动窗口机制如何影响爬虫性能?TCP滑动窗口机制对爬虫性能有多方面影响:1)提高吞吐量,允许在未收到确认时发送多个数据包,减少等待时间;2)优化带宽利用率,避免因等待确认导致的带宽闲置;3)结合拥塞控制机制,动态调整窗口大小适应网络状况;4)减少网络往返延迟,特别是在高延迟网络环境下;5)与HTTP Keep-Alive配合,在单个TCP连接上传输多个HTTP请求,减少连接建立开销;6)合理的窗口大小设置能平衡传输效率与资源占用,过小会降低吞吐量,过大可能导致拥塞;7)影响TCP缓冲区管理,爬虫可调整缓冲区大小优化性能;8)与Nagle算法和延迟确认协同工作,但可能需要针对爬虫场景进行参数调整;9)零窗口问题需要特别处理,避免接收方处理速度跟不上数据到达速度;10)良好的TCP拥塞控制能帮助爬虫在高并发场景下避免触发网络限制。 UDP 在爬虫中有哪些潜在应用场景?UDP在爬虫中的潜在应用场景包括:1) DNS查询,爬虫通过UDP进行域名解析;2) 大规模数据采集,利用UDP的高效率快速收集数据;3) 网络发现和端口扫描,快速探测目标主机;4) 分布式爬虫系统中的节点通信;5) 实时监控和数据收集,利用UDP的低延迟特性;6) 高频率数据更新场景;7) 多播/广播数据获取,一次性接收多个数据源;8) 需要容忍一定数据丢失的高效率场景;9) 访问仅支持UDP的网络服务;10) 快速探测网站可用性。 DNS 的解析过程如何影响爬虫效率?DNS解析过程对爬虫效率有多方面影响:1)延迟问题:完整的DNS解析需要多次网络请求(从本地缓存到根域名服务器),每次带来几十到几百毫秒延迟,频繁访问不同域名时这些延迟会累积显著降低效率;2)连接数限制:浏览器对同时进行的DNS请求数量有限制,爬虫可能遇到DNS瓶颈无法充分利用带宽;3)缓存利用:合理利用DNS缓存可提高效率,爬虫可手动维护域名-IP映射表避免重复解析;4)CDN和负载均衡:现代网站使用CDN可能导致同一域名解析到不同IP,增加复杂性但提供更好性能;5)DNS污染和劫持:某些地区DNS可能被污染,爬虫需处理这种情况并使用可靠DNS服务器;6)并发请求优化:通过预解析域名、使用连接池和会话复用可减少DNS解析影响;7)加密DNS协议:DoH/DoT提供更好隐私但可能增加延迟。优化措施包括:实现DNS缓存、使用连接池、预解析域名、异步DNS解析、选择高性能DNS服务器、实现重试机制、批量解析和使用本地hosts文件。 什么是 DNS 污染,如何在爬虫中应对?DNS污染(DNS Spoofing或DNS Poisoning)是一种网络攻击技术,攻击者通过向DNS缓存中插入错误的DNS记录,使用户访问特定网站时被重定向到恶意或错误的IP地址。这干扰了域名系统的正常解析过程。 在爬虫中应对DNS污染的方法: 1. 使用可信的DNS服务(如Google DNS 8.8.8.8、Cloudflare DNS 1.1.1.1) 2. 实施短DNS缓存超时,减少使用被污染记录的时间 3. 坚持使用HTTPS,即使DNS被污染也能验证服务器身份 4. 实现IP白名单机制,验证解析结果 5. 从多个DNS源获取解析结果并交叉验证 6. 使用DNS over HTTPS (DoH)或DNS over TLS (DoT)加密查询 7. 通过VPN或代理服务器绕过可能被污染的本地DNS 8. 实现IP轮换,定期更换爬虫使用的IP地址 9. 定期验证域名解析结果,发现异常及时切换 10. 实现健康检查机制,监控目标网站可访问性 WebSocket 协议在爬虫中有哪些应用场景?WebSocket协议在爬虫中有多种应用场景:1) 实时数据抓取,如股票行情、体育比分等;2) 获取动态加载的内容,超越传统HTTP请求的限制;3) 作为REST API的高效替代方案;4) 监控聊天应用和社交媒体的实时消息流;5) 抓取在线游戏或直播平台的实时数据;6) 采集物联网设备的实时数据流;7) 进行网站性能监控和自动化测试;8) 更真实地模拟用户行为,结合WebSocket和HTTP请求实现完整交互流程。 HTTP/3 的 QUIC 协议对爬虫有何影响?HTTP/3的QUIC协议对爬虫有显著影响:1) 连接建立更快(0-RTT),提高爬取效率但也更容易触发速率限制;2) 多路复用和队头阻塞解决,使爬虫能更高效地利用带宽;3) 基于UDP的特性使爬虫流量模式更灵活但也更容易被识别为自动化流量;4) 连接迁移特性让爬虫在IP切换时保持连接状态,可能使反爬虫更难检测;5) 内置加密增加了安全但也增加了计算开销。爬虫需要调整策略以适应这些变化,包括更精细的请求频率控制和更接近人类用户的行为模式。 如何在爬虫中处理 TLS 证书验证失败?处理爬虫中的 TLS 证书验证失败有几种方法:1) 禁用验证(不推荐用于生产环境):Python requests 库中使用 verify=False 参数;Scrapy 中设置 ssl_verify = False。2) 提供自定义 CA 证书:使用 verify='/path/to/cacert.pem' 指定证书包。3) 处理异常:捕获 requests.exceptions.SSLError 并实现重试逻辑。4) 证书固定:预先保存目标网站证书指纹并验证。5) 更新证书信任库:更新系统 CA 证书或下载最新证书包。注意:禁用验证会降低安全性,应谨慎使用。 什么是 HTTP 的 Content-Security-Policy 头,如何绕过?Content-Security-Policy (CSP) 是一个HTTP安全头,用于帮助网站防止跨站脚本(XSS)、点击劫持和其他代码注入攻击。它通过指定哪些资源(脚本、样式、图像等)可以被加载和执行来限制攻击面。 CSP通过一系列指令定义策略,如: • default-src: 默认资源策略 • script-src: 脚本来源 • style-src: 样式来源 • img-src: 图像来源 • connect-src: 连接来源 • frame-src: 嵌套框架来源 关于绕过CSP(仅用于授权安全测试): 1. 利用不安全配置: 如unsafe-inline、unsafe-eval或过于宽松的通配符策略 2. 利用白名单漏洞: 找到被允许但不安全的域名 3. 利用遗留功能: 如HTML注释、SVG中的脚本、data: URI等 4. 服务器错误配置: 如CSP头未正确验证或缓存问题 5. 利用浏览器漏洞: 某些浏览器可能存在CSP实现缺陷 6. 利用其他HTTP头: 通过Content-Type头等方式混淆 注意: 绕过CSP通常违反法律法规,仅应在明确授权的安全测试环境中使用。 如何在爬虫中处理 IPv6 地址的请求?在爬虫中处理IPv6地址的请求,需要注意以下几点: 1. 确认环境支持IPv6:使用socket.has_ipv6检查Python环境是否支持IPv6。 2. 使用支持IPv6的HTTP客户端库:如requests、urllib、aiohttp或httpx等库默认都支持IPv6。 3. IPv6地址的特殊处理:IPv6地址在URL中需要用方括号括起来,例如:http://[2001:db8::1]:8080/。 4. 示例代码: 复制代码 隐藏代码
import requests
import socket
# 直接通过IPv6地址请求
url = "http://[2001:db8::1]:8080/"
try:
response = requests.get(url, timeout=10)
print(response.status_code)
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
# 通过DNS解析获取IPv6地址
hostname = "example.com"
try:
addr_info = socket.getaddrinfo(hostname, 80, socket.AF_INET6)
ipv6_addr = addr_info[0][4][0]
url = f"http://[{ipv6_addr}]/"
response = requests.get(url, timeout=10)
print(response.status_code)
except (socket.gaierror, requests.exceptions.RequestException) as e:
print(f"请求失败: {e}")5. 处理连接问题:实现重试机制、设置合理的超时时间,考虑使用代理解决网络连接问题。 6. 错误处理:处理IPv6特有的错误,实现IPv6不可用时的降级策略。 HTTP 的 Expect-CT 头在爬虫中有何意义?Expect-CT(证书透明度)头在爬虫中有多方面意义:首先,它帮助爬虫验证网站是否实施了证书透明度政策,增强SSL/TLS连接的安全性检测;其次,爬虫可利用此头评估网站的安全性和可信度,识别潜在的安全风险;第三,对于需要合规性检查的爬虫任务,Expect-CT头可作为网站安全合规性的一个指标;此外,了解此头配置有助于爬虫更准确地模拟浏览器行为,避免被反爬虫机制识别;最后,爬虫可以监控Expect-CT头的变化,及时发现网站安全配置的变更,为安全审计提供数据支持。 如何在爬虫中处理 HTTP 的 451 Unavailable For Legal Reasons?在爬虫中处理 HTTP 451 'Unavailable For Legal Reasons' 状态码需要采取以下方法: 1. 识别和记录:在爬虫代码中检查响应状态码,当遇到 451 时进行特殊处理并记录这些 URL 和原因。 2. 尊重法律限制:不要尝试绕过法律限制(如使用代理或更改 User-Agent),这可能导致法律问题。 3. 调整爬取策略:跳过这些受限制的内容,更新爬虫的排除列表避免重复尝试访问。 4. 寻找替代数据源:记录缺失的数据,寻找其他合法获取相关信息的途径。 5. 代码实现示例(Python): 复制代码 隐藏代码
import requests
deffetch_url(url):
try:
response = requests.get(url, timeout=10)
if response.status_code == 451:
print(f"法律限制: {url} - {response.reason}")
# 记录到日志文件
log_restricted_url(url, response.reason)
returnNone
elif response.status_code == 200:
return response.text
else:
returnNone
except Exception as e:
print(f"请求 {url} 时出错: {str(e)}")
returnNone
deflog_restricted_url(url, reason):
withopen("restricted_urls.log", "a") as f:
f.write(f"{url} - {reason}\n")6. 法律咨询:如果涉及大量 451 响应,建议咨询法律专业人士了解相关法规。 7. 长期策略:建立合规审查流程,考虑实施地理围栏避免在某些司法管辖区访问受限内容。 HTTP 的 Alt-Svc 头在爬虫中有何用途?HTTP的Alt-Svc头(Alternative Service)在爬虫中有以下几方面用途:1) 协议升级,允许爬虫使用更高效的协议如HTTP/2或HTTP/3获取资源;2) 负载均衡,将爬虫请求分散到不同的服务器或CDN节点;3) 故障转移,当主服务不可用时引导爬虫使用备用服务;4) 地理优化,指示爬虫使用地理位置更近的服务器减少延迟;5) 资源优化,为特定资源提供更高效的服务端点。爬虫应合理使用这些机制,同时遵守网站的robots.txt和使用条款。 如何在爬虫中实现 HTTP/2 的 Server Push?在爬虫中实现 HTTP/2 的 Server Push 需要以下几个步骤: 1. 选择支持 HTTP/2 的客户端库: • Python: 使用 httpx、requests-http2 或 aiohttp • Node.js: 使用 http2 模块 • Java: 使用 HttpClient 5+ 或 OkHttp 2. 配置客户端启用 HTTP/2: 复制代码 隐藏代码
# Python 示例 (httpx)
import httpx
client = httpx.Client(http2=True)
response = client.get("https://example.com")3. 处理服务器推送的资源: • 监听 PUSH_PROMISE 帧 • 接收并缓存推送的资源 • 避免重复请求已推送的资源 4. 注意事项: • 不是所有服务器都支持 Server Push • 某些 CDN 和反向代理可能禁用 Server Push • 现代浏览器已逐渐弃用此特性 • 需要合理处理推送资源的缓存和生命周期 5. 高级实现: • 使用 HTTP/2 的流控制和优先级设置 • 实现资源预测算法,提高推送效率 • 自定义中间件处理推送的资源 HTTP 的 Strict-Transport-Security 头如何影响爬虫?HTTP Strict-Transport-Security (HSTS) 头对爬虫有多方面影响:1) 强制使用HTTPS连接,爬虫必须通过安全协议访问网站,否则会收到重定向或连接失败;2) 要求有效的SSL/TLS证书,爬虫必须正确处理证书验证;3) 若设置includeSubDomains参数,所有子域名也必须通过HTTPS访问;4) 影响爬虫灵活性,特别是在需要临时切换到HTTP的开发环境中;5) 可能降低爬虫性能,因为HTTPS连接需要额外的SSL/TLS握手;6) 爬虫需要正确处理HSTS的max-age参数,即在指定时间内只能使用HTTPS;7) 对于预加载到浏览器HSTS列表的网站,爬虫即使首次访问也必须使用HTTPS。这些因素都要求爬虫能够正确处理HTTPS连接和SSL证书验证。 如何在爬虫中处理 HTTP 的 413 Payload Too Large?处理HTTP 413 Payload Too Large错误的方法有:1) 减小请求体大小,分批请求数据;2) 修改请求头,如添加Accept-Encoding启用压缩;3) 实现分块传输编码;4) 添加指数退避重试机制;5) 使用代理或IP轮换;6) 降低爬取速度,增加请求间隔;7) 使用流式处理大文件下载;8) 优化数据格式,使用更高效的序列化方式;9) 只请求必要字段而非全部数据;10) 考虑实现分布式爬取分散负载。 HTTP 的 X-XSS-Protection 头在爬虫中有何意义?X-XSS-Protection 头在爬虫中有以下几方面的意义: 1. 网站安全策略指示:爬虫可以通过这个头部了解目标网站是否启用了XSS防护机制,这有助于评估网站的安全级别。 2. 反爬虫检测:某些网站可能会检查请求是否包含适当的X-XSS-Protection头来识别非浏览器行为。高级爬虫可能需要伪造这个头部以更好地模拟真实浏览器。 3. 数据处理方式:如果网站设置了X-XSS-Protection为1; mode=block,爬虫获取的数据可能已经过XSS过滤,这会影响数据的原始性和完整性。 4. 安全研究:对于安全研究人员,这个头部可以作为评估网站安全实践的一个指标。 5. 合规性评估:爬虫可以通过检查这个头部来了解网站是否符合某些安全合规要求。 需要注意的是,随着现代浏览器逐渐弃用X-XSS-Protection而转向内容安全策略(CSP),这个头部在爬虫中的实际意义已经有所降低。 如何在爬虫中处理 HTTP 的 416 Range Not Satisfiable?处理HTTP 416 Range Not Satisfiable错误的方法包括: 1. 检测416错误状态码并捕获异常 2. 禁用范围请求:在请求头中移除'Range'字段,改用完整下载 3. 实现重试机制:当收到416错误时,重新获取资源实际大小并调整下载策略 4. 验证资源大小:先发送HEAD请求获取Content-Length,再计算合适的范围 5. 使用分块下载:将大文件分成多个小块下载,每个块独立处理 6. 检查资源是否被修改:实现ETag或Last-Modified检查,避免过时数据 7. 降级处理:当范围请求不可用时,切换到普通下载模式 8. 实现指数退避重试:遇到416错误后,等待一段时间再重试 HTTP 的 Content-Range 头在爬虫断点续传中有何作用?HTTP的Content-Range头在爬虫断点续传中起着关键作用。当爬虫使用Range头请求资源的部分内容时,服务器通过Content-Range头返回以下信息:1) 标识返回内容在整个资源中的位置和范围,格式为'bytes start-end/total';2) 配合206 Partial Content状态码表示这是一个部分响应;3) 帮助爬虫将多个部分正确组合成完整资源;4) 在请求范围无效时(416状态码),提供资源实际大小帮助调整请求;5) 使爬虫能够精确跟踪下载进度,计算已下载字节数和总字节数,从而实现高效、可靠的断点续传功能。 如何在爬虫中处理 HTTP 的 417 Expectation Failed?HTTP 417 Expectation Failed 表示服务器无法满足请求头中Expect字段的期望值。处理方法:1) 移除Expect请求头,如headers中不包含'Expect'字段;2) 使用try-except捕获417错误后移除Expect头重试;3) 禁用100-continue机制(如requests中设置stream=False);4) 实现重试机制,遇到417时自动重试;5) 使用更底层的HTTP客户端库进行更精细控制。最佳实践是避免发送Expect头并实现适当的错误处理机制。 HTTP 的 Access-Control-Allow-Origin 在爬虫中有何影响?Access-Control-Allow-Origin 是 CORS(跨域资源共享)机制中的关键响应头,在爬虫中有以下影响: 1. 浏览器环境爬虫的影响:使用Puppeteer、Selenium等基于浏览器的爬虫工具时,若目标网站未设置适当的CORS头,浏览器会阻止跨域请求,导致爬虫无法获取数据。 2. 非浏览器环境爬虫的影响:使用requests、urllib等库的直接HTTP请求不受CORS限制,可以绕过此限制直接获取资源。 3. 反爬虫策略:网站可通过CORS限制特定域的访问,作为简单的反爬手段。即使允许跨域,服务器也可能通过检查Origin/Referer头拒绝爬虫请求。 4. 预检请求处理:对于复杂请求(自定义头、非简单方法等),浏览器会发送OPTIONS预检请求,爬虫需正确处理此类请求才能成功获取数据。 5. 配置风险:若网站使用通配符(*)过于宽松配置CORS,可能导致敏感数据暴露,但也可能使爬虫更容易获取数据。 6. JSONP替代方案:不支持CORS的旧系统可能使用JSONP,爬虫需识别并处理这种特殊的数据格式。 总之,CORS对爬虫的影响取决于实现方式:浏览器环境爬虫必须处理CORS限制,而非浏览器环境爬虫通常不受此影响,但仍需应对网站可能的其他反爬措施。 如何在爬虫中处理 HTTP 的 426 Upgrade Required?处理HTTP 426 Upgrade Required状态码的几种方法: 1. 自动协议升级:检测到426响应后,将HTTP请求自动转换为HTTPS请求 复制代码 隐藏代码
if response.status_code == 426:
https_url = url.replace("http://", "https://")
response = requests.get(https_url)2. 遵循响应头中的Upgrade字段:解析响应头中的Upgrade字段,了解需要升级到的协议 复制代码 隐藏代码
if response.status_code == 426:
upgrade_header = response.headers.get('Upgrade')
print(f"服务器要求升级到: {upgrade_header}")3. 使用支持协议升级的HTTP客户端库:如httpx、aiohttp等,它们内置了协议升级支持 4. 设置适当的请求头:在初始请求中添加Connection: Upgrade头部 复制代码 隐藏代码
headers = {'Connection': 'Upgrade'}
response = requests.get(url, headers=headers)5. 实现重试机制:对426响应进行自动重试,避免因协议不匹配导致的请求失败 HTTP 的 X-Content-Type-Options 头在爬虫中有何意义?X-Content-Type-Options 头(通常设置为 'nosniff')在爬虫中的意义主要体现在以下几个方面:1) 防止内容类型混淆,确保爬虫严格按照服务器声明的 Content-Type 处理资源,而不是尝试猜测或嗅探类型;2) 提高爬虫解析的可靠性,避免因 MIME 类型猜测错误导致的解析失败;3) 保证不同爬虫处理内容的一致性,减少因各自嗅探算法差异导致的处理差异;4) 虽然主要是为浏览器设计,但在某些情况下也能增强爬虫处理资源的安全性,防止可能利用类型嗅探的漏洞。 如何在爬虫中处理 HTTP 的 428 Precondition Required?在爬虫中处理HTTP 428 Precondition Required状态码,需要遵循以下步骤: 1. 理解428状态码的含义: • 428表示服务器要求请求必须满足某些先决条件才能处理 • 通常是为了防止客户端修改过时的数据版本 2. 检查响应头: • 查看'Precondition-Required'响应头 • 查找服务器提供的其他相关信息,如'Retry-After'或具体的条件要求 3. 获取当前资源状态: • 如果需要先获取资源的当前版本信息,发送HEAD或GET请求获取ETag或Last-Modified值 • ETag是资源的唯一标识符,Last-Modified是资源的最后修改时间 4. 构造条件请求: • 在后续请求中添加适当的条件头: • 'If-Match': 用于PUT或DELETE请求,确保资源ETag与指定值匹配 • 'If-None-Match': 用于GET或HEAD请求,确保资源ETag与指定值不匹配 • 'If-Modified-Since': 用于GET或HEAD请求,确保资源在指定时间后未被修改 • 'If-Unmodified-Since': 用于PUT或DELETE请求,确保资源在指定时间前未被修改 5. 处理重试: • 如果服务器提供了'Retry-After'头,等待指定的时间后再重试 • 实现适当的退避策略,避免频繁请求 6. 代码示例(Python使用requests库): 复制代码 隐藏代码
import requests
from time import sleep
# 第一次请求获取ETag
response = requests.get('http://example.com/resource')
etag = response.headers.get('ETag')
# 如果遇到428,使用条件请求重试
if response.status_code == 428:
# 等待重试时间(如果有)
retry_after = response.headers.get('Retry-After')
if retry_after:
sleep(int(retry_after))
# 使用条件头重试
headers = {'If-Match': etag}
response = requests.get('http://example.com/resource', headers=headers)7. 异常处理: • 实现适当的错误处理逻辑 • 考虑请求失败后的重试机制 HTTP 的 Content-Encoding 头在爬虫数据解压中有何作用?HTTP的Content-Encoding头在爬虫数据解压中起着关键作用。它指示服务器对响应体使用了哪种压缩算法(如gzip、deflate、br等),使爬虫能够正确选择解压方法。正确识别这个头部可以确保爬虫成功解压压缩数据,减少传输时间,提高效率,并避免因解压错误导致的数据损坏。现代爬虫框架通常自动处理这个头部,但在自定义爬虫时,需要根据这个头部的值选择相应的解压库或函数来处理压缩数据。 如何在爬虫中处理 HTTP 的 431 Request Header Fields Too Large?处理HTTP 431错误(请求头字段过大)的几种方法:1) 精简请求头,移除非必要字段如过长的User-Agent或多个Accept-*头;2) 分批发送请求头,避免一次性发送过多信息;3) 减少Cookie数量,只发送必要的认证信息;4) 实现重试机制,捕获431错误后精简请求头再重试;5) 使用代理或轮换User-Agent分散请求;6) 增加请求间隔,避免触发服务器限流;7) 查看目标网站文档了解其请求头限制并相应调整。 HTTP 的 X-DNS-Prefetch-Control 头在爬虫中有何用途?X-DNS-Prefetch-Control 头在爬虫中主要用于控制 DNS 预取行为,具有以下用途:1) 优化性能:通过控制是否提前解析域名,减少实际请求时的延迟;2) 资源管理:可以禁用不必要的 DNS 预取以节省网络资源;3) 提高爬取效率:对于需要访问多个域名的爬虫,适当的预取可以显著提升速度;4) 模拟真实用户:遵循网站的 DNS 预取指示,使爬虫行为更接近普通浏览器;5) 避免检测:减少异常的 DNS 查询模式,降低被反爬系统识别的风险。 如何在爬虫中处理 HTTP 的 508 Loop Detected?HTTP 508 Loop Detected 表示服务器检测到了请求循环,通常是由于服务器配置问题导致的重定向循环。处理方法包括:1) 检查URL是否正确,避免请求路径错误;2) 实现请求重试机制但设置最大重试次数限制(如3次);3) 使用指数退避策略增加重试间隔时间;4) 轮换User-Agent和请求头,避免被识别为爬虫;5) 实现代理IP池,切换不同IP发送请求;6) 设置合理的超时时间;7) 添加请求间隔,模拟人类行为;8) 记录错误日志,分析特定模式;9) 使用会话(Session)保持连接;10) 检查并避免无限重定向循环。代码上可以使用try-catch捕获508错误,并在达到最大重试次数后跳过该URL或标记为无效。 HTTP 的 Server-Timing 头在爬虫性能分析中有何作用?HTTP 的 Server-Timing 头在爬虫性能分析中具有多方面的重要作用: 1. 性能监控与诊断:提供服务器处理请求的详细时间分解,帮助爬虫开发者识别性能瓶颈,如慢查询、高延迟API调用等。 2. 请求优化:通过分析Server-Timing数据,爬虫可以调整请求频率和并发数,优先爬取响应较快的端点,实现更智能的爬虫调度。 3. 反爬策略分析:帮助理解网站的反爬机制,识别哪些操作触发了额外处理时间,从而调整爬虫策略以避免触发反爬措施。 4. 负载感知:服务器可能通过Server-Timing指示当前负载情况,爬虫可根据这些信息调整抓取频率,实现更礼貌的爬虫行为。 5. 缓存策略优化:指示缓存命中率和服务端生成时间,帮助爬虫区分静态和动态内容,优化爬取频率。 6. 合规性监控:监控爬虫请求对目标服务器的影响,确保爬虫行为符合网站使用条款,避免过度请求导致服务器问题。 7. API调用优化:对于API驱动的网站,揭示各API端点的性能特征,帮助优化API调用顺序和频率。 通过合理利用Server-Timing头,爬虫可以实现更高效、稳定的运行,同时减少对目标服务器的负担。 如何在爬虫中处理 HTTP 的 511 Network Authentication Required?HTTP 511 'Network Authentication Required' 表示客户端需要先对网络进行身份验证才能访问资源。在爬虫中处理此错误的方法如下: 1. 识别 511 错误:捕获 HTTP 511 状态码,检查响应内容通常包含认证表单 2. 处理认证流程: • 分析认证页面的表单结构 • 提取必要的认证参数(用户名、密码、隐藏字段等) • 向认证服务器发送认证请求 3. 代码示例(Python requests): 复制代码 隐藏代码
import requests
from bs4 import BeautifulSoup
defhandle_511_auth(url, credentials):
session = requests.Session()
# 尝试访问目标URL
response = session.get(url)
# 如果是511错误,处理认证
if response.status_code == 511:
soup = BeautifulSoup(response.text, 'html.parser')
form = soup.find('form')
# 提取表单数据和action
form_data = {}
forinputin form.find_all('input'):
name = input.get('name')
value = input.get('value', '')
if name:
form_data[name] = value
form_data.update(credentials)
action = form.get('action', url)
# 提交认证
auth_response = session.post(action, data=form_data)
# 认证后再次尝试访问原始URL
return session.get(url)
return response4. 使用注意事项: • 确保你有权限访问目标网络 • 分析认证页面的实际结构,可能需要调整表单提交逻辑 • 处理认证后的 cookies 维护会话 • 对于复杂的认证(如JavaScript重定向),可能需要使用Selenium等工具 HTTP 的 Public-Key-Pins 头在爬虫中有何意义?HTTP Public-Key-Pins (HPKP) 头在爬虫中具有重要意义:首先,它增强了爬虫的安全性,通过强制验证网站公钥哈希值,防止中间人攻击和伪造证书;其次,爬虫需要实现HPKP缓存和验证机制,确保只连接到使用已验证密钥的网站;第三,这增加了爬虫的复杂性,需要处理密钥轮换和HPKP验证失败的情况;最后,遵守网站的HPKP策略已成为合规爬虫的基本要求,有助于建立更可靠的网络爬取环境。 如何在爬虫中实现 HTTP 的 Expect-CT 验证?在爬虫中实现 HTTP 的 Expect-CT 验证需要以下几个步骤: 1. 理解 Expect-CT 头部: • Expect-CT 头部格式为:Expect-CT: max-age=seconds, enforce, report-uri="URL" • max-age: 指定客户端应记住CT策略的时间(秒) • enforce: 表示客户端必须强制执行CT验证 • report-uri: 指定违反CT策略时应报告的URL 2. 使用支持 Expect-CT 的 HTTP 客户端: Python 中可以使用 requests 或 httpx 库,它们默认会处理 Expect-CT 头部。 3. 实现验证逻辑: 复制代码 隐藏代码
import requests
deffetch_with_expect_ct(url):
try:
response = requests.get(url, verify=True)
# 检查响应中的 Expect-CT 头部
expect_ct = response.headers.get('Expect-CT')
if expect_ct:
print(f"服务器发送的 Expect-CT 头部: {expect_ct}")
# 解析头部参数
parts = expect_ct.split(',')
max_age = None
enforce = False
report_uri = None
for part in parts:
part = part.strip()
if part.startswith('max-age='):
max_age = int(part.split('=')[1])
elif part == 'enforce':
enforce = True
elif part.startswith('report-uri='):
report_uri = part.split('=')[1].strip('"')
print(f"Max-Age: {max_age}, Enforce: {enforce}, Report URI: {report_uri}")
# 根据 enforce 参数决定是否验证
if enforce:
# 这里可以添加额外的验证逻辑
print("必须执行 CT 验证")
return response.text
except requests.exceptions.SSLError as e:
print(f"SSL 错误(可能由于 CT 验证失败): {e}")
returnNone
# 使用示例
url = "https://example.com"
content = fetch_with_expect_ct(url)4. 处理 CT 报告: 如果服务器提供了 report-uri,你可能需要实现一个端点来接收这些报告: 复制代码 隐藏代码
from flask import Flask, request
app = Flask(__name__)
@app.route('/ct-report', methods=['POST'])
def handle_ct_report():
report_data = request.json
# 处理报告数据
print(f"收到 CT 报告: {report_data}")
return "OK", 2005. 注意事项: • 确保爬虫遵守网站的 robots.txt 和使用条款 • 考虑添加适当的延迟以避免对目标服务器造成过大负担 • 处理可能出现的异常和错误情况 • 考虑使用会话和连接池以提高性能 HTTP的Feature-Policy头在爬虫中有何影响?HTTP的Feature-Policy头对爬虫有多方面影响:1) 功能限制:可能阻止爬虫使用摄像头、麦克风、地理位置等API;2) 资源加载控制:限制从特定来源加载资源,影响爬虫获取数据的能力;3) 沙箱环境:创建更严格的JavaScript执行环境,影响基于JS的爬虫;4) 浏览器兼容性:不同爬虫工具对Feature-Policy的支持程度各异;5) 合规性:爬虫应尊重这些策略以避免违反网站条款;6) 反爬虫措施:网站可能利用此作为阻止自动化工具的手段。爬虫开发者需要了解这些限制,并可能需要调整策略或使用支持绕过限制的工具。 如何在爬虫中处理 HTTP 的 421 Misdirected Request?处理HTTP 421 Misdirected Request可以采取以下策略:1) 检查URL是否正确,服务器可能已更改地址;2) 实现带延迟和最大重试次数的重试机制,因为此错误可能是暂时的;3) 尝试更换User-Agent,某些服务器可能拒绝特定UA;4) 检查代理设置,必要时更换代理或直接连接;5) 如果响应包含Location头部,尝试重定向到新地址;6) 降低请求频率,避免服务器过载;7) 实现退避策略,多次遇到错误时增加重试间隔;8) 确保使用服务器支持的HTTP协议版本。 HTTP 的 Clear-Site-Data 头在爬虫中有何意义?HTTP 的 Clear-Site-Data 头在爬虫中有以下几个重要意义:1) 帮助爬虫清除访问过程中留下的数据痕迹(如cookies、localStorage等),减少被追踪的风险;2) 使爬虫行为更接近真实浏览器,表明爬虫会清除会话数据,降低被反爬系统识别的概率;3) 支持负责任的爬虫行为,遵守网站的数据清理政策;4) 在GDPR等数据保护法规下,确保爬虫不存储不必要的用户数据;5) 对于网站开发者而言,了解此头有助于设计更智能的反爬策略或识别恶意爬虫。需要注意的是,Clear-Site-Data 主要是服务器发送给客户端的指示,而非爬虫直接使用的工具。 如何在爬虫中处理 HTTP 的 423 Locked?处理 HTTP 423 Locked 状态码(表示资源被锁定)的爬虫策略包括:1) 实现指数退避重试机制,随重试次数增加等待时间;2) 使用代理IP轮换,避免基于IP的锁定;3) 降低请求频率,减少触发锁定的可能;4) 检查并优化请求头,确保符合服务器期望;5) 实现分布式爬虫系统,由不同节点轮流请求;6) 记录锁定状态,分析模式并调整策略;7) 如果可能,了解锁定原因并等待解锁;8) 确保爬虫行为遵守robots.txt规定;9) 使用会话管理或重置会话;10) 在必要时联系网站管理员获取访问许可。 HTTP 的 Cross-Origin-Resource-Policy 头如何影响爬虫?Cross-Origin-Resource-Policy (CORP) 头通过限制跨域资源访问来影响爬虫操作。具体影响包括:1) 当网站设置 'same-origin' 或 'same-site' 策略时,爬虫从不同域名发起的请求会被拒绝;2) 爬虫需要处理由此产生的 CORS 错误;3) 爬虫可能需要使用代理服务器或调整请求策略来绕过这些限制。然而,爬虫开发者应当尊重网站的访问规则,避免过度请求,并优先考虑使用合规的爬虫技术,而不是试图绕过安全措施。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的限流?处理HTTP 429 Too Many Requests错误的方法包括:1) 检测429状态码并解析Retry-After头确定等待时间;2) 实现指数退避算法,如等待时间=基础延迟×(2^重试次数);3) 使用请求队列控制发送频率,添加随机延迟(0.5-2秒);4) 实现令牌桶或漏桶算法控制请求速率;5) 轮换User-Agent和IP地址;6) 添加真实浏览器请求头;7) 使用会话管理维护cookies;8) 遵守robots.txt中的爬虫延迟指令;9) 使用Scrapy等框架的内置限流功能;10) 监控错误频率并动态调整策略。 HTTP 的 Timing-Allow-Origin 头在爬虫中有何用途?Timing-Allow-Origin 头是 HTTP 响应头,用于控制哪些来源可以访问资源的性能计时信息。在爬虫中,它的主要用途包括:1) 允许爬虫获取跨域资源的精确加载时间,有助于性能分析和监控;2) 帮助爬虫工具遵守网站的安全策略,尊重服务器对计时信息访问的限制;3) 优化爬虫策略,通过分析不同资源的加载时间来调整爬取顺序和效率;4) 支持网站性能分析工具,使其能够全面评估包含跨域资源的网站性能。爬虫在使用此信息时应注意遵守相关爬取规范,避免对目标网站造成过大负担。 如何在爬虫中处理 HTTP 的 499 Client Closed Request?处理爬虫中的499 Client Closed Request(客户端关闭请求)可以从以下几个方面入手:1) 降低请求频率,增加请求间隔时间;2) 设置合理的超时参数,避免长时间等待;3) 使用异步请求机制,避免阻塞;4) 实现智能重试机制,但控制重试频率;5) 优化请求头,如设置Connection: keep-alive;6) 使用分布式爬虫分散负载;7) 完善错误处理和日志记录;8) 遵守robots.txt规则;9) 使用代理IP池轮换请求;10) 优化爬取策略,减少不必要的请求。499错误通常表示服务器处理请求时间过长,客户端已提前关闭连接,因此核心思路是提高爬虫效率并减少对服务器的压力。 HTTP 的 X-Permitted-Cross-Domain-Policies 头在爬虫中有何意义?X-Permitted-Cross-Domain-Policies 头在爬虫中的意义主要体现在以下几个方面:1) 它指示了网站对跨域访问的限制,帮助爬虫了解哪些资源可以跨域访问;2) 作为合规性参考,爬虫需要尊重这些策略以避免违反网站政策;3) 影响爬虫对特定类型资源(如Flash内容或PDF文档)的处理方式;4) 可能是网站反爬虫机制的一部分,爬虫需要识别并遵守这些限制;5) 帮助爬虫设计者确保其行为不会无意中绕过网站的安全措施;6) 在某些情况下可能与数据保护法规相关,爬虫需考虑法律因素。总的来说,这个头帮助爬虫在获取数据的同时保持合法合规。 如何在爬虫中处理 HTTP 的 451 Unavailable For Legal Reasons?处理HTTP 451错误(由于法律原因不可用)的策略包括:1)识别并尊重法律限制,不尝试绕过;2)记录遇到451的URL以便后续分析;3)调整爬取策略,跳过受限内容;4)使用代理和IP轮换;5)添加适当的请求头;6)严格遵守robots.txt规则;7)优先考虑使用官方API;8)实现适当的错误处理和重试机制;9)必要时咨询法律专业人士;10)记录和分析错误模式以优化爬虫行为。最重要的是确保爬虫操作合法合规。 HTTP 的 Referrer-Policy 头如何影响爬虫?HTTP 的 Referrer-Policy 头通过控制 Referer 头的发送方式对爬虫产生多方面影响:1) 限制来源信息:当网站设置严格策略(如 no-referrer)时,爬虫请求资源可能导致目标服务器无法识别请求来源,影响需要验证来源的API访问;2) 影响链式爬取:使用 same-origin 或 origin 等策略时,跨域请求只发送有限信息,可能影响依赖完整来源信息的爬虫逻辑;3) 干扰反爬机制:网站可能通过 Referer 检测爬虫,爬虫需正确设置 Referer 头以避免被识别;4) 影响资源加载:某些依赖 Referer 验证合法性的资源可能因策略而无法加载;爬虫应对策略包括正确设置 Referer 头、处理不同策略、遵守 robots.txt 以及尊重网站设置的隐私保护意图。 如何在爬虫中实现 HTTP 的 Expect-CT 验证?在爬虫中实现 HTTP 的 Expect-CT 验证可以通过以下几种方式: 1. 使用 requests 库: 复制代码 隐藏代码
import requests
headers = {
'User-Agent': 'MyCrawler/1.0',
'Expect-CT': 'max-age=86400, enforce, report-uri="https://example.com/ct-report"'
}
response = requests.get('https://example.com', headers=headers)
# 检查响应头
if 'Expect-CT' in response.headers:
print('服务器支持 Expect-CT:', response.headers['Expect-CT'])2. 在 Scrapy 爬虫中通过中间件实现: 复制代码 隐藏代码
class ExpectCTMiddleware:
def process_request(self, request, spider):
request.headers.setdefault('Expect-CT', 'max-age=86400, enforce')
return None
def process_response(self, request, response, spider):
if 'Expect-CT' in response.headers:
spider.logger.debug('服务器支持 Expect-CT')
return response3. 使用 aiohttp 进行异步爬虫: 复制代码 隐藏代码
import aiohttp
headers = {
'User-Agent': 'MyCrawler/1.0',
'Expect-CT': 'max-age=86400, enforce'
}
async with aiohttp.ClientSession() as session:
async with session.get('https://example.com', headers=headers) as response:
if 'Expect-CT' in response.headers:
print('服务器支持 Expect-CT')4. 处理强制执行模式下的证书验证错误: 复制代码 隐藏代码
try:
response = requests.get('https://example.com', headers=headers, verify=True)
except requests.exceptions.SSLError as e:
print(f'证书验证失败: {e}')Expect-CT 头格式为:max-age=<seconds>, enforce, report-uri="<uri>",其中 enforce 表示强制执行模式,不符合CT策略的证书将被拒绝。 HTTP 的 Cross-Origin-Opener-Policy 头在爬虫中有何影响?Cross-Origin-Opener-Policy (COOP) 头在爬虫中会产生多方面影响:1) 当设置为'same-origin'或'deny'时,会限制跨源窗口交互,可能导致爬虫无法获取完整页面内容;2) 影响JavaScript渲染,因为现代爬虫工具(如Puppeteer)使用的无头浏览器可能被隔离,导致执行环境受限;3) 可能阻碍跨源资源加载,影响数据提取;4) 可能被用作反爬虫机制,阻止自动化工具访问;5) 与Cross-Origin-Embedder-Policy (COEP)结合使用时,会启用跨源隔离,增加爬取难度。爬虫开发者需要调整策略或寻找替代方案(如使用API)来应对这些限制。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的动态限流?处理 HTTP 429 Too Many Requests 的动态限流可以采取以下策略: 1. 检测并响应 429 状态码:在爬虫代码中捕获 429 错误,解析响应头中的 Retry-After 字段,确定需要等待的时间。 2. 实现动态延迟机制: • 基于服务器响应动态调整请求间隔 • 实现指数退避算法,每次遇到限流时等待时间加倍 • 使用自适应速率控制,根据成功率调整请求频率 3. 使用成熟的爬虫框架: • Scrapy 的 AutoThrottle 扩展可自动调整请求延迟 • 实现基于服务器响应时间的动态速率限制 4. 分布式爬取与代理轮换: • 使用多个 IP 地址分散请求压力 • 实现请求队列和分布式爬取架构 5. 遵守 robots.txt: • 检查并遵守网站的爬取规则 • 设置合理的 User-Agent 和请求间隔 6. 使用速率限制库: • 使用如 ratelimit、pyrate-limiter 等库实现令牌桶或漏桶算法 7. 监控与日志记录: • 记录 429 错误频率和响应时间 • 根据历史数据优化爬取策略 8. 设置合理的爬取时段: • 避开网站流量高峰期 • 根据目标网站特点调整爬取时间表 HTTP 的 CORP 头在爬虫中有何意义?CORP(Cross-Origin Read Policy)头是HTTP响应头,用于控制跨域资源共享策略,在爬虫场景中有以下意义:1) 访问控制:网站可通过CORP头限制爬虫访问权限,防止未授权抓取;2) 数据保护:对敏感数据实施来源限制,防止数据滥用;3) 反爬虫机制:作为反爬策略的一部分,保护内容安全和服务器负载;4) 安全增强:减少跨域攻击风险,提高数据安全性;5) 合规性:帮助网站满足数据保护法规要求;6) 资源保护:防止图片、视频等资源被其他网站直接引用。对爬虫开发者而言,理解CORP意味着需遵守网站访问政策,处理跨域访问限制,并确保爬虫的合规性和道德性。 如何在爬虫中处理 HTTP 的 418 I'm a teapot?HTTP 48 'I'm a teapot' 是一个非标准状态码,通常表示服务器拒绝请求,可能是反爬虫机制。处理方法包括:1) 降低请求频率,添加随机延迟;2) 更换User-Agent模拟真实浏览器;3) 使用代理IP避免IP封锁;4) 添加完整的浏览器请求头;5) 处理可能出现的验证码;6) 使用会话管理保持cookies;7) 检查并遵守robots.txt;8) 实现合理的重试机制;9) 考虑使用官方API代替爬虫;10) 调整爬取策略使其更符合网站预期。 HTTP 的 X-Robots-Tag 头在爬虫中有何作用?X-Robots-Tag 是一个 HTTP 响应头,用于向搜索引擎爬虫传递指令,控制它们如何处理网页内容。其主要作用包括:1) 通过 'noindex' 指示爬虫不要索引特定页面;2) 使用 'nofollow' 指示爬虫不要跟随页面上的链接;3) 针对特定资源类型设置指令,如 'noimageindex' 阻止图片被索引;4) 提供比 robots.txt 更细粒度的控制,可以针对单个页面而非整个目录;5) 与 robots.txt 协同工作,提供更全面的爬虫控制;6) 解决 robots.txt 无法控制内容索引的局限性。它允许网站管理员直接通过 HTTP 头部传递爬虫指令,特别适用于没有 robots.txt 文件或需要针对特定页面设置规则的情况。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的自适应限流?处理 429 Too Many Requests 的自适应限流可以采取以下方法: 1. 识别并响应 429 状态码:立即暂停请求并检查响应头中的 Retry-After 字段,获取建议的等待时间。 2. 实现令牌桶或漏桶算法:控制请求速率,使请求以固定速率发出,避免突发流量。 3. 指数退避策略:每次收到 429 后,等待时间按指数增长(如1s, 2s, 4s, 8s),同时加入随机性避免同步请求。 4. 动态调整请求间隔:根据最近收到的 429 频率自动调整请求间隔,高频率时增加间隔,低频率时适当减少。 5. 请求队列管理:实现请求缓冲队列,当检测到限流时,将请求放入队列等待合适时机发送。 6. 用户代理和IP轮换:使用代理IP池和不同的User-Agent分散请求来源。 7. 监控和日志记录:记录429响应的出现频率和模式,用于优化限流策略。 8. 遵守robots.txt:解析并遵守目标网站的爬取规则,尊重Crawl-delay指令。 9. 模拟人类行为:在请求间加入随机延迟,模拟人类浏览行为模式。 10. 分布式协调:如果是分布式爬虫,确保各节点协调工作,避免集中请求同一资源。 HTTP 的 Cross-Origin-Embedder-Policy 头在爬虫中有何影响?Cross-Origin-Embedder-Policy (COEP) 头对爬虫有多方面影响:1) 资源获取限制:当设置为'require-corp'时,只允许加载返回了Cross-Origin-Resource-Policy头的资源,可能导致爬虫无法获取某些跨域资源;2) JavaScript渲染障碍:使用无头浏览器(如Puppeteer)的爬虫可能因COEP限制而无法完全渲染页面,影响动态内容获取;3) 反爬虫机制:网站可能利用COEP作为反爬策略,阻止自动化工具获取完整内容;4) 技术兼容性:传统爬虫工具可能不完全支持COEP,导致功能受限;5) 性能影响:额外的策略验证可能增加爬虫请求时间;6) 合规要求:爬虫需遵守COEP策略,避免违反网站使用条款。爬虫开发者可能需要调整策略,如使用支持COEP的浏览器引擎或寻找替代数据获取方式。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的分布式限流?处理HTTP 429 Too Many Requests的分布式限流需要多层次的策略: 1. Redis分布式限流:使用Redis的原子操作实现令牌桶或漏桶算法,协调多个爬虫节点。 2. 中央队列调度:建立中央请求队列,由调度器按适当速率分发请求到各节点。 3. 滑动窗口算法:实现基于时间窗口的限流,统计全局请求速率。 4. 自适应退避策略:收到429错误时,解析Retry-After头并实现指数退避算法。 5. 分层限流控制:实现全局、域名级和URL级的多层限流。 6. 请求分散与随机化:在多个IP间分散请求,随机化请求间隔避免固定模式。 7. 监控与动态调整:监控请求成功率,动态调整限流参数。 关键实现包括使用Redis的原子操作确保分布式一致性,实现智能重试机制,以及结合IP轮换和User-Agent轮换降低被检测的风险。 HTTP的NEL头在爬虫网络错误日志中有何用途?NEL(Network Error Logging)头在爬虫网络错误日志中有多种用途:1)错误监控与诊断,帮助开发者识别爬虫在抓取过程中遇到的网络问题;2)性能分析,通过收集的错误数据评估爬虫在不同网络条件下的表现;3)问题定位,识别特定URL或模式下的网络问题;4)改进爬虫策略,基于错误数据调整重试机制、超时设置等参数;5)网络质量评估,分析目标网站在不同网络环境下的可访问性;6)合规性监控,确保爬虫遵守robots.txt等规则;7)安全监控,检测网站对爬虫的限制措施;8)负载均衡优化,帮助识别表现不佳的服务器或数据中心。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的指数退避?处理爬虫中的HTTP 429 Too Many Requests错误时,指数退避算法是一种有效策略。以下是实现方法: 1. 基本原理:每次收到429错误后,等待时间按指数增长(基础延迟 × 2^重试次数) 2. 实现步骤: • 解析响应头中的Retry-After(服务器指定重试时间) • 如果没有Retry-After,使用指数退避算法计算等待时间 • 添加随机抖动避免多爬虫同步重试 • 等待后重试请求,直到达到最大重试次数 3. 代码示例: 复制代码 隐藏代码
import time
import random
defhandle_429_retry(retry_count, base_delay=1, max_delay=60):
delay = base_delay * (2 ** retry_count)
# 添加随机抖动(±10%)
jitter = random.uniform(-0.1, 0.1) * delay
delay = min(delay + jitter, max_delay)
return delay
defmake_request(url, max_retries=5):
retry_count = 0
while retry_count <= max_retries:
try:
response = requests.get(url)
if response.status_code != 429:
return response
# 使用服务器指定的时间或指数退避
delay = int(response.headers.get('Retry-After', 0)) or handle_429_retry(retry_count)
print(f"等待 {delay:.2f} 秒后重试...")
time.sleep(delay)
retry_count += 1
except Exception as e:
print(f"请求出错: {str(e)}")
returnNone
return None4. 优化建议: • 优先使用服务器指定的Retry-After头 • 设置最大延迟时间避免过长等待 • 在分布式爬虫中增加更多随机性 • 监控429错误频率动态调整策略 HTTP 的 Reporting-Endpoints 头在爬虫中有何意义?HTTP的Reporting-Endpoints头在爬虫中有多方面的意义:1) 它为网站和爬虫之间提供了一种正式的通信渠道,使网站能够向爬虫发送关于使用政策的反馈;2) 爬虫开发者可以通过此机制接收违规警告,及时调整爬取策略以避免被封禁;3) 它支持更智能的反爬虫策略,网站可以发送警告或限制请求而非直接封禁IP;4) 有助于提高爬虫的合规性,确保爬取行为符合网站的使用条款和法律法规;5) 爬虫可以通过报告端点提交问题反馈,促进与网站管理者的良性互动;6) 在遵守robots.txt规则的同时,提供了一种更灵活的沟通方式;7) 有助于建立负责任的爬取行为,维护互联网生态系统的健康发展。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的令牌桶算法?在爬虫中使用令牌桶算法处理429 Too Many Requests错误,主要步骤如下: 1. 令牌桶原理:令牌桶以固定速率生成令牌,每个请求消耗一个令牌,桶有最大容量限制,允许突发流量。 2. 实现步骤: • 初始化令牌桶:设置容量和令牌生成速率 • 请求前获取令牌:发送HTTP请求前检查是否有可用令牌 • 处理429错误:收到429时,根据Retry-After字段等待 • 动态调整:根据服务器响应调整请求速率 3. 代码示例: 复制代码 隐藏代码
class TokenBucket:
def__init__(self, capacity, refill_rate):
self.capacity = capacity
self.refill_rate = refill_rate
self.tokens = capacity
self.last_refill_time = time.time()
self.lock = Lock()
defconsume(self, tokens=1):
withself.lock:
now = time.time()
elapsed = now - self.last_refill_time
new_tokens = elapsed * self.refill_rate
self.tokens = min(self.capacity, self.tokens + new_tokens)
self.last_refill_time = now
ifself.tokens >= tokens:
self.tokens -= tokens
returnTrue
returnFalse
defwait_for_token(self, tokens=1):
withself.lock:
whileself.tokens < tokens:
now = time.time()
elapsed = now - self.last_refill_time
new_tokens = elapsed * self.refill_rate
self.tokens = min(self.capacity, self.tokens + new_tokens)
self.last_refill_time = now
ifself.tokens < tokens:
wait_time = (tokens - self.tokens) / self.refill_rate
time.sleep(wait_time)4. 爬虫集成: • 在发送请求前调用wait_for_token方法 • 收到429错误时,根据Retry-After等待后重试 • 实现自适应速率调整机制 5. 高级考虑: • 多线程环境下的线程安全 • 分布式爬虫中的全局速率控制 • 结合robots.txt和User-Agent轮换 • 实现指数退避策略处理持续429错误 通过令牌桶算法,爬虫可以平滑控制请求速率,避免触发服务器的速率限制,提高爬取成功率和稳定性。 HTTP 的 Permissions-Policy 头在爬虫中有何影响?HTTP 的 Permissions-Policy 头对爬虫有多方面的影响: 1. 功能访问限制:Permissions-Policy 头可以限制浏览器 API 的使用,如地理位置、摄像头、麦克风等。爬虫如果模拟浏览器行为并尝试使用这些受限 API,可能会遇到功能不可用的情况。 2. 影响无头浏览器渲染:现代爬虫常使用无头浏览器(如 Headless Chrome)来渲染 JavaScript。Permissions-Policy 可能会限制这些环境中的某些功能,导致爬虫无法获取完整的动态加载内容。 3. 自动化检测:网站可以通过 Permissions-Policy 限制特定功能(如访问传感器、支付功能等),使自动化工具更容易被识别,从而实现反爬虫策略。 4. 存储访问限制:爬虫可能依赖 localStorage、IndexedDB 等存储机制来维护会话状态。Permissions-Policy 可以限制对这些存储的访问,干扰爬虫的状态管理。 5. 跨域资源访问:Permissions-Policy 可以限制跨域 iframe 或脚本访问某些功能,这可能影响爬虫从第三方资源中获取数据的能力。 6. JavaScript 执行环境:爬虫执行的 JavaScript 可能会因 Permissions-Policy 改变的环境特性而表现异常,影响数据提取的准确性。 7. 反爬虫机制:作为网站安全策略的一部分,Permissions-Policy 可以与其他反爬虫措施结合使用,增加爬虫获取数据的难度。 8. 影响 API 调用:某些爬虫可能通过浏览器 API 获取数据,Permissions-Policy 限制这些 API 的使用会直接影响爬虫的数据采集能力。 爬虫开发者需要了解这些限制,并可能需要调整爬虫策略,如使用不同的用户代理、绕过特定限制或寻找替代的数据获取方法。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的滑动窗口限流?处理HTTP 429 Too Many Requests的滑动窗口限流可以采取以下方法: 1. 检测429响应并提取Retry-After信息: • 当收到429响应时,检查响应头中的Retry-After字段 • 如果没有Retry-After,使用默认退避时间(如5-60秒) 2. 实现滑动窗口限流算法: • 维护一个时间窗口(如60秒)和该窗口内的请求数量 • 在发送新请求前,检查当前窗口内的请求数是否已达到限制 • 如果已达到限制,计算需要等待的时间并休眠 3. 动态调整请求速率: • 根据服务器返回的限制信息(如X-RateLimit-Remaining)动态调整请求间隔 • 实现请求队列,按固定间隔从队列中取出请求发送 4. 随机化请求间隔: • 在固定间隔基础上添加随机延迟(±20%),避免被检测为自动化爬虫 • 例如:如果间隔为1秒,实际延迟可以是0.8-1.2秒之间的随机值 5. 实现指数退避算法: • 当连续收到429错误时,以指数方式增加等待时间(如2^N秒) • 成功发送请求后重置退避计数器 6. 使用分布式限流(如果适用): • 如果爬虫是分布式的,实现基于共享存储的限流机制 • 如使用Redis等工具记录各节点的请求情况 7. 尊重robots.txt和API限制: • 在发送请求前检查robots.txt文件 • 遵循API文档中的速率限制建议 8. 实现请求重试机制: • 对429错误进行有限次数的重试 • 每次重试间增加等待时间 示例代码(Python): 复制代码 隐藏代码
import time
import random
from collections import deque
classsliding_window_rate_limiter:
def__init__(self, window_size=60, max_requests=30):
self.window_size = window_size # 时间窗口大小(秒)
self.max_requests = max_requests # 窗口内最大请求数
self.requests = deque() # 存储请求时间戳的双端队列
self.retry_after = 0# 服务器返回的等待时间
self.backoff = 0# 指数退避计数器
self.last_request_time = 0# 上次请求时间
defcan_request(self):
now = time.time()
# 清理过期请求
whileself.requests and now - self.requests[0] > self.window_size:
self.requests.popleft()
# 如果有退避时间未结束,不能请求
ifself.retry_after > 0and now < self.last_request_time + self.retry_after:
returnFalse
# 如果窗口内请求数已达上限,不能请求
iflen(self.requests) >= self.max_requests:
returnFalse
returnTrue
defwait_if_needed(self):
ifnotself.can_request():
# 计算需要等待的时间
wait_time = 0
# 如果有退避时间,使用退避时间
ifself.retry_after > 0:
wait_time = self.retry_after - (time.time() - self.last_request_time)
# 如果窗口内请求数已达上限,计算窗口剩余时间
iflen(self.requests) >= self.max_requests:
oldest_request = self.requests[0]
wait_time = max(wait_time, oldest_request + self.window_size - time.time())
# 添加随机延迟(±20%)
wait_time *= random.uniform(0.8, 1.2)
if wait_time > 0:
time.sleep(wait_time)
defrecord_request(self, retry_after=None):
now = time.time()
self.requests.append(now)
self.last_request_time = now
if retry_after:
self.retry_after = retry_after
self.backoff += 1# 增加退避计数器
else:
self.retry_after = 0
self.backoff = 0# 重置退避计数器
# 使用示例
limiter = sliding_window_rate_limiter(window_size=60, max_requests=30)
for url in urls:
limiter.wait_if_needed()
try:
response = requests.get(url)
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 5))
limiter.record_request(retry_after)
else:
limiter.record_request()
# 处理响应
except Exception as e:
# 处理异常
passHTTP 的 Cross-Origin-Resource-Sharing 头在爬虫中有何作用?CORS(跨域资源共享)头主要用于解决浏览器中的同源策略限制,但在爬虫中的作用有限:1) 大多数爬虫库不受CORS限制,因为它们不遵循浏览器的同源安全策略;2) 爬虫通常不会自动发送或处理CORS相关的头部;3) 即使目标网站设置了严格的CORS策略,通常也无法阻止爬虫获取资源;4) CORS对爬虫的影响主要体现在需要模拟浏览器行为的场景,如执行JavaScript渲染内容的网站;5) 爬虫可以通过不发送Origin头部或使用代理来绕过CORS限制。简而言之,CORS主要是浏览器安全机制,对传统爬虫影响较小。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的漏桶算法?处理HTTP 429 Too Many Requests错误使用漏桶算法的步骤: 1. 理解漏桶算法原理: • 桶有固定容量,表示最大允许的请求数 • 请求以任意速率流入桶中 • 请求以固定速率从桶中流出 • 桶满时,新请求需要等待或被丢弃 2. 实现漏桶算法: • 创建桶结构,记录当前请求数量和最后处理时间 • 设置桶容量(如100个请求)和漏出速率(如每秒10个请求) • 每次发送请求前检查桶的状态 • 如果桶已满,计算需要等待的时间 3. 处理429响应: • 解析响应头中的Retry-After字段,获取建议等待时间 • 根据Retry-After调整桶的漏出速率 • 记录限流信息,动态调整爬取策略 4. 代码实现示例: 复制代码 隐藏代码
import time
classLeakyBucket:
def__init__(self, capacity, rate):
self.capacity = capacity # 桶容量
self.rate = rate # 漏出速率(请求/秒)
self.water = 0# 当前请求数量
self.last_leak = time.time() # 上次漏出时间
defleak(self):
# 计算应该漏掉多少请求
now = time.time()
elapsed = now - self.last_leak
leak_count = elapsed * self.rate
self.water = max(0, self.water - leak_count)
self.last_leak = now
defcan_request(self):
self.leak()
returnself.water < self.capacity
defadd_request(self):
ifself.can_request():
self.water += 1
returnTrue
returnFalse
defwait_time(self):
# 计算还需等待多久才能发送请求
self.leak()
ifself.water < self.capacity:
return0
return (self.water - self.capacity + 1) / self.rate5. 在爬虫中的使用: 复制代码 隐藏代码
# 初始化漏桶
bucket = LeakyBucket(capacity=100, rate=10)
# 发送请求前检查
ifnot bucket.can_request():
wait = bucket.wait_time()
time.sleep(wait)
# 发送请求并处理响应
try:
response = send_request(url)
if response.status_code == 429:
retry_after = int(response.headers.get('Retry-After', 60))
time.sleep(retry_after)
# 可以调整桶的参数
bucket.rate = 1 / retry_after # 根据Retry-After调整速率
except Exception as e:
# 错误处理
pass6. 最佳实践: • 结合其他限流算法如令牌桶提高效率 • 实现动态调整策略,根据服务器响应自动调整 • 设置合理的User-Agent和请求头 • 考虑使用代理IP池分散请求 • 遵守robots.txt规则 HTTP 的 X-Download-Options 头在爬虫文件下载中有何意义?X-Download-Options 是一个 HTTP 响应头,通常设置为 'X-Download-Options: noopen'。在爬虫文件下载中,它的主要意义体现在以下几个方面:1) 安全防护:防止下载的文件被直接执行,降低爬虫无意中运行恶意代码的风险;2) 合规性:尊重网站设置的安全限制,避免违反网站使用条款;3) 文件处理:指导爬虫将下载内容保存到磁盘而非尝试执行;4) 模拟真实浏览器行为:使爬虫行为更接近真实用户,提高隐蔽性。当爬虫遇到此头部时,应避免直接打开或执行下载的文件,而是将其保存到本地后再进行后续处理。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的固定窗口限流?处理HTTP 429 Too Many Requests的固定窗口限流有几种有效方法: 1. 基本请求延迟:在每次请求后添加固定延迟,如每分钟限制60个请求则每次请求后等待1秒。 2. 动态延迟调整:基于服务器返回的Retry-After头信息动态调整延迟时间,并添加随机性避免所有爬虫同步重试。 3. 令牌桶算法:实现令牌桶算法更平稳地控制请求速率,避免突发流量触发的限流。 4. 固定窗口计数器:精确模拟固定窗口限流,在每个时间窗口内限制请求数量。 5. 使用爬虫框架:利用Scrapy等框架内置的限流机制,如AUTOTHROTTLE_ENABLED。 6. 分布式限流:在分布式爬虫中使用Redis等工具协调各节点的请求频率。 7. 结合代理和请求头:使用代理轮换和随机请求头减少被识别为爬虫的风险。 8. 自适应限流:根据服务器响应自动调整请求频率,遇到429时增加延迟,成功一段时间后尝试减小延迟。 最佳实践包括:尊重Retry-After头信息、添加随机延迟、监控请求频率、使用专业限流库、在分布式环境中协调请求、优雅降级而非完全停止。 HTTP 的 Content-Security-Policy-Report-Only 头在爬虫中有何用途?Content-Security-Policy-Report-Only (CSP-RO) 头在爬虫中有多种用途:1) 安全策略分析 - 爬虫可以检测网站的安全策略而不被阻止访问资源;2) 合规性测试 - 模拟 CSP-RO 头测试网站策略是否过于严格;3) 安全审计 - 收集违规报告识别潜在漏洞;4) 监控和日志 - 帮助管理员了解资源加载问题;5) 策略优化 - 收集触发违规的信息帮助调整更精确的安全策略;6) 竞争对手分析 - 了解其他网站的安全策略;7) 安全研究 - 收集分析各类网站的 CSP 报告了解安全趋势。使用时需遵守网站 robots.txt 和服务条款,避免过度请求造成负担。 HTTP 的 X-Content-Security-Policy 头在爬虫中有何影响?X-Content-Security-Policy (CSP) 头对爬虫有多方面影响:1) 限制资源加载来源,可能阻止爬虫获取完整页面内容;2) 禁止内联脚本执行,影响JavaScript渲染的爬虫工具;3) 限制iframe等嵌入内容,影响嵌套内容抓取;4) 限制连接端点,可能阻止AJAX数据获取;5) 增加网站对自动化工具的检测能力;6) 可能影响表单提交和数据收集。爬虫开发者需调整策略,如设置真实User-Agent、启用JavaScript执行、处理认证cookie、遵守robots.txt、控制请求频率等。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的自适应重试?处理HTTP 429 Too Many Requests的自适应重试策略包括: 1. 检测与响应头解析:捕获429状态码并解析响应头中的'Retry-After'字段,该字段可能包含重试等待时间(秒数)或具体日期。 2. 智能等待机制:根据'Retry-After'值设置等待时间,若没有该字段,则采用指数退避算法(如第一次等待1秒,第二次2秒,第三次4秒等)。 3. 请求限流控制:实现速率限制器(如令牌桶算法),在发送请求前检查是否允许发送,避免触发429错误。 4. 随机化延迟:在固定间隔基础上添加随机抖动(jitter),避免所有请求同时重试形成新的请求高峰。 5. IP/代理轮换:当IP被限流时,切换到不同的IP地址或使用代理池分散请求压力。 6. 动态调整策略:监控429错误率,动态调整请求频率;实现最大重试次数限制,避免无限重试。 7. 分布式协调:在分布式爬虫中,使用共享存储(如Redis)协调各节点的请求速率,避免整体超出限制。 8. 尊重robots.txt:检查并遵守目标网站的爬取规则,合理设置User-Agent和请求头。 这些策略组合使用可以有效避免触发429错误,提高爬虫的稳定性和效率。 HTTP 的 X-WebKit-CSP 头在爬虫中有何意义?X-WebKit-CSP(X-WebKit-Content-Security-Policy)是内容安全策略(CSP)的早期实现,在爬虫中具有重要意义:1) 它限制资源加载来源,可能阻碍爬虫获取完整页面资源;2) 禁止内联脚本执行,影响需要运行JavaScript的动态内容抓取;3) 作为反爬虫机制的一部分,可阻止自动化工具访问;4) 爬虫需理解并遵守这些策略以避免被封禁;5) 现代爬虫需处理CSP策略以有效模拟真实浏览器行为;6) CSP常与其他反爬虫技术结合使用,形成综合防御系统。爬虫开发者需在遵守网站安全策略与有效抓取内容间找到平衡。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的动态重试?处理 HTTP 429 Too Many Requests 错误的动态重试策略包括以下几个关键步骤: 1. 检测 429 错误:监控 HTTP 响应状态码,识别 429 错误。 2. 解析 Retry-After 头:从响应头中提取 'Retry-After' 字段,它可能包含秒数或具体的重试时间点。 3. 实现动态等待:根据解析到的信息设置等待时间,如未提供则使用指数退避算法(如 2^retry_count 秒)。 4. 添加重试限制:设置最大重试次数避免无限循环。 5. 实现装饰器模式:创建可重用的重试装饰器: 复制代码 隐藏代码
import functools
import time
from datetime import datetime
defretry_on_429(max_retries=5):
defdecorator(func):
@functools.wraps(func)
defwrapper(*args, **kwargs):
retry_count = 0
while retry_count < max_retries:
response = func(*args, **kwargs)
if response.status_code != 429:
return response
retry_after = response.headers.get('Retry-After')
if retry_after:
try:
wait_time = int(retry_after)
except ValueError:
try:
retry_date = datetime.strptime(retry_after, '%a, %d %b %Y %H:%M:%S GMT')
wait_time = (retry_date - datetime.utcnow()).total_seconds()
except ValueError:
wait_time = 60
else:
wait_time = min(2 ** retry_count, 60)
time.sleep(wait_time)
retry_count += 1
raise Exception(f"Max retries ({max_retries}) exceeded due to rate limiting")
return wrapper
return decorator6. 使用框架内置功能:如 Scrapy 的 AutoThrottle 扩展或 requests 的 Session 配置。 7. 考虑分布式协调:在分布式爬虫中使用共享存储协调请求速率。 8. 记录和监控:记录速率限制事件,持续优化策略。 HTTP 的 X-Frame-Options 头在爬虫中有何作用?X-Frame-Options 头在爬虫中有以下几个方面的作用:1) 防止内容被嵌入:通过设置 DENY 或 SAMEORIGIN 值,网站可以防止其内容被 iframe 或 frame 嵌入,间接限制了爬虫通过框架方式获取内容的能力;2) 作为反爬虫策略的一部分:网站可能将其与其他技术结合使用,增加爬虫获取数据的难度;3) 内容保护:防止爬虫将网站内容嵌入到其他平台或应用中;4) 安全防护:虽然主要是安全机制,但也间接影响了爬虫的行为方式。需要注意的是,大多数爬虫库(如 requests)默认不会像浏览器一样严格遵守此头部,除非有专门处理逻辑。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的指数退避重试?处理 HTTP 429 Too Many Requests 的指数退避重试是爬虫开发中的重要技能,以下是实现方法: 1. 基本指数退避算法:每次重试的等待时间呈指数增长,例如第一次1秒,第二次2秒,第三次4秒,以此类推。 2. 优先使用 Retry-After 头:检查服务器响应中的 Retry-After 头,优先使用服务器建议的延迟时间。 3. 添加随机性:在指数退避基础上加入随机延迟(如 ±0.5秒),避免多个爬虫同时重试造成"惊群效应"。 4. 设置最大延迟上限:避免等待时间过长影响爬取效率。 5. 设置最大重试次数:防止无限重试浪费资源。 Python 实现示例: 复制代码 隐藏代码
import time
import random
import requests
deffetch_with_retry(url, max_retries=5, initial_delay=1, max_delay=60):
retries = 0
delay = initial_delay
while retries < max_retries:
try:
response = requests.get(url)
if response.status_code == 200:
return response
elif response.status_code == 429:
# 检查Retry-After头
retry_after = response.headers.get('Retry-After')
if retry_after:
try:
delay = min(float(retry_after), max_delay)
except ValueError:
pass
else:
# 指数退避 + 随机性
delay = min(delay * 2 + random.uniform(0, 1), max_delay)
print(f"收到429错误,将在{delay:.2f}秒后重试...")
time.sleep(delay)
retries += 1
else:
return response
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
delay = min(delay * 2 + random.uniform(0, 1), max_delay)
time.sleep(delay)
retries += 1
print(f"达到最大重试次数 {max_retries},放弃请求")
return None6. 高级优化: • 使用代理池分散请求 • 设置请求头模拟浏览器行为 • 实现分布式爬虫协调 • 使用 Scrapy 等框架的中间件机制 这种策略能有效避免触发服务器的限流机制,提高爬虫的稳定性和效率。 HTTP 的 X-Content-Duration 头在爬虫中有何用途?X-Content-Duration 是一个非标准的HTTP头字段,用于指示内容的预期持续时间或长度,通常以秒为单位。在爬虫中,这个头字段有以下用途:1) 内容筛选和优先级排序,爬虫可以根据内容时长决定抓取优先级;2) 带宽和资源管理,帮助预估下载内容所需的资源;3) 内容分类,将不同时长的内容(如短视频、长视频等)分开处理;4) 遵守爬取政策,如果robots.txt规定了只允许爬取特定时长的内容;5) 性能优化,对长时间内容采用特殊处理方式。需要注意的是,由于X-Content-Duration不是标准HTTP头,并非所有网站都会提供此信息。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的固定重试?处理爬虫中的429 Too Many Requests错误需要实现一个带有固定重试策略的机制。以下是关键实现步骤: 1. 识别429错误:捕获HTTP 429状态码 2. 解析Retry-After头:从响应中获取服务器建议的等待时间 3. 实现重试机制:在遇到429错误时,按照建议时间延迟后重试 4. 设置最大重试次数:避免无限重试导致程序卡死 Python实现示例: 复制代码 隐藏代码
import time
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
defcreate_session_with_retry(max_retries=3):
session = requests.Session()
retry_strategy = Retry(
total=max_retries,
status_forcelist=[429],
backoff_factor=1
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
return session
deffetch_with_retry(url, max_retries=3):
session = create_session_with_retry(max_retries)
for attempt inrange(max_retries):
try:
response = session.get(url)
if response.status_code == 429:
retry_after = response.headers.get('Retry-After', 5)
delay = int(retry_after) if retry_after.isdigit() else5
print(f"遇到429错误,等待 {delay} 秒后重试...")
time.sleep(delay)
continue
return response
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
if attempt == max_retries - 1:
raise
return None关键点: • 使用Retry-After头获取服务器建议的等待时间 • 实现指数退避策略作为后备方案 • 设置合理的最大重试次数 • 添加适当的日志记录以便调试 HTTP 的 X-Content-Security 头在爬虫中有何意义?X-Content-Security-Policy (CSP) 头在爬虫中有多方面意义:1) 限制资源加载,可能影响爬虫获取数据的完整性;2) 防止内容篡改,保护爬虫免受某些攻击;3) 影响JavaScript执行,对依赖JS渲染的爬虫(如无头浏览器)有直接影响;4) 控制iframe/frame加载,影响页面解析;5) 可能限制表单提交,影响需要填写表单的爬虫;6) 限制某些API使用,要求爬虫调整数据获取策略;7) 提出合规性考量,爬虫开发者需权衡遵守CSP与获取数据的关系。爬虫应尊重网站的CSP策略,同时考虑如何在不违反网站政策的前提下有效获取所需数据。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的随机重试?处理HTTP 429 Too Many Requests错误的随机重试策略包括: 1. 检测429错误:捕获状态码429并解析响应头中的Retry-After字段(如果有) 2. 实现随机延迟:使用随机延迟代替固定延迟,避免触发更多限制 • 基础延迟 = 服务器建议等待时间(或默认值) • 总延迟 = 基础延迟 + 随机增量(如0~基础延迟的50%) 3. 指数退避算法:每次重试延迟时间逐渐增加 • delay = (2^attempt) + random.uniform(0, 1) 4. 随机重试限制:设置最大重试次数(通常3-5次) 5. 请求头随机化:每次重试随机更换User-Agent和请求头 6. IP/代理轮换:如有代理,重试时切换不同IP 7. 示例代码(Python): 复制代码 隐藏代码
import time
import random
import requests
deffetch_with_retry(url, max_retries=5):
for attempt inrange(max_retries):
try:
if attempt > 0:
# 解析Retry-After或使用随机延迟
retry_after = response.headers.get('Retry-After', 2)
delay = float(retry_after) + random.uniform(0, retry_after/2)
time.sleep(delay)
# 随机User-Agent
headers = {
'User-Agent': random.choice(user_agent_pool)
}
response = requests.get(url, headers=headers)
if response.status_code == 429:
continue# 触发重试
return response
except Exception as e:
if attempt == max_retries - 1:
raise
time.sleep((2 ** attempt) + random.uniform(0, 1))8. 高级策略:实现请求队列、令牌桶算法控制请求速率,或使用分布式爬虫分散请求 HTTP 的 X-DNS-Prefetch-Control 头在爬虫中有何作用?X-DNS-Prefetch-Control 头在爬虫中主要有以下作用:1) 控制DNS预获取行为,可设为'off'减少不必要的DNS查询,提高爬取效率;2) 帮助爬虫模拟浏览器行为,避免因缺少该头而被网站识别为爬虫;3) 在大规模爬取时,禁用DNS预获取可减少系统资源消耗;4) 增加爬虫的匿名性,减少网站收集DNS记录的机会。使用requests库时可通过headers参数设置此头。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的自适应指数退避?处理HTTP 429 Too Many Requests的自适应指数退避策略包括以下关键步骤: 1. 基础指数退避算法:每次遇到429错误时, exponentially 增加等待时间,例如:2^1秒、2^2秒、2^3秒... 2. 实现自适应调整: • 检查响应头中的Retry-After字段,优先使用服务器建议的等待时间 • 根据历史成功率调整延迟(成功率低时增加延迟) • 添加随机抖动(jitter)避免多个客户端同步重试 3. Python实现示例: 复制代码 隐藏代码
class AdaptiveBackoff:
def__init__(self, max_retries=5, base_delay=1, max_delay=60):
self.max_retries = max_retries
self.base_delay = base_delay
self.max_delay = max_delay
self.history = []
defwait_time(self, attempt, retry_after=None):
if retry_after:
try:
returnmin(int(retry_after), self.max_delay)
except ValueError:
pass
delay = self.base_delay * (2 ** attempt)
jitter = delay * random.uniform(0.1, 0.5)
delay += jitter
returnmin(delay, self.max_delay)
deffetch(self, url):
attempt = 0
while attempt < self.max_retries:
try:
response = requests.get(url)
if response.status_code == 429:
retry_after = response.headers.get('Retry-After')
delay = self.wait_time(attempt, retry_after)
time.sleep(delay)
attempt += 1
continue
return response
except requests.exceptions.RequestException:
delay = self.wait_time(attempt)
time.sleep(delay)
attempt += 1
raise Exception(f"Failed after {self.max_retries} attempts")4. Scrapy框架实现:通过自定义DownloaderMiddleware处理429状态码并应用退避策略 5. 最佳实践: • 设置合理的最大重试次数和最大延迟时间 • 实现请求速率限制,避免触发429错误 • 使用代理池和User-Agent轮换 • 遵守robots.txt规则和网站API的使用条款 HTTP 的 X-Download-Options 头在爬虫中有何用途?X-Download-Options 头(通常值为 'noopen')在爬虫中主要用于限制爬虫对下载内容的直接访问。它的主要用途包括:1) 防止爬虫直接打开下载的文件(如PDF、Excel等)而必须通过下载流程获取;2) 增加爬取难度,使爬虫需要额外处理下载过程;3) 保护受版权或使用限制的资源;4) 帮助网站检测爬虫行为,因为正常浏览器会遵循此头的指示。爬虫在遇到设置了此头的网站时,可能需要调整策略,模拟浏览器行为或处理下载对话框。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的动态指数退避?处理HTTP 429 Too Many Requests错误的动态指数退避策略如下: 1. 基本指数退避算法:每次遇到429错误后,等待时间按指数增长,例如: 复制代码 隐藏代码
import time
def exponential_backoff(retry_count, base_delay=1, max_delay=60):
delay = min(base_delay * (2 ** retry_count), max_delay)
time.sleep(delay)2. 添加随机抖动(jitter):避免多个爬虫同步退避: 复制代码 隐藏代码
import random
def jittered_backoff(retry_count, base_delay=1, max_delay=60):
delay = min(base_delay * (2 ** retry_count), max_delay)
jittered_delay = delay * (0.5 + random.random() * 0.5) # 50%-100%的随机延迟
time.sleep(jittered_delay)3. 结合Retry-After头:如果服务器提供了Retry-After值,优先使用它: 复制代码 隐藏代码
def handle_429(response, retry_count=0):
if response.status_code == 429:
if 'Retry-After' in response.headers:
delay = int(response.headers['Retry-After'])
else:
delay = min(1 * (2 ** retry_count), 60)
time.sleep(delay)
return True
return False4. 完整实现示例: 复制代码 隐藏代码
import time
import random
import requests
deffetch_with_backoff(url, max_retries=5):
retry_count = 0
while retry_count <= max_retries:
try:
response = requests.get(url)
if response.status_code == 429:
if'Retry-After'in response.headers:
delay = int(response.headers['Retry-After'])
else:
delay = min(1 * (2 ** retry_count), 60)
# 添加随机抖动
delay = delay * (0.5 + random.random() * 0.5)
print(f"429错误,等待 {delay:.2f} 秒后重试...")
time.sleep(delay)
retry_count += 1
continue
response.raise_for_status()
return response
except requests.exceptions.RequestException as e:
if retry_count == max_retries:
raise e
retry_count += 1
time.sleep(min(1 * (2 ** retry_count), 60))5. 高级策略: • 实现请求计数器,在达到阈值前主动降低请求频率 • 根据目标网站特性调整基础延迟和最大延迟 • 使用分布式锁协调多个爬虫实例 • 实现自适应算法,根据历史响应时间动态调整参数 HTTP 的 X-Permitted-Cross-Domain-Policies 头在爬虫中有何作用?X-Permitted-Cross-Domain-Policies 头在爬虫中主要用于控制跨域访问行为,具体作用包括:1) 定义哪些域名可以访问网站资源;2) 限制爬虫获取跨域数据;3) 作为反爬虫机制的一部分,阻止未授权的跨域抓取;4) 帮助爬虫理解网站的访问政策,确保合规抓取;5) 控制Flash等技术的跨域数据访问。该头通常设置为'none'、'master-only'、'by-content-type'或'all'等不同值,表示不同程度的跨域访问限制。爬虫在抓取时应尊重这些策略,避免违反网站规则。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的自适应滑动窗口?在爬虫中处理429 Too Many Requests的自适应滑动窗口方法包括: 1. 基本实现原理: • 监控服务器响应的429错误和返回的重试时间(Retry-After头) • 动态调整请求窗口大小和请求间隔 • 实现请求队列的平滑控制 2. 核心实现步骤: • 初始化一个初始窗口大小(如5个请求) • 记录每个请求的时间戳 • 当收到429错误时,提取Retry-After值 • 根据错误信息调整窗口大小或增加等待时间 • 实现指数退避算法,如等待时间 = 基础延迟 × (2 ^ 重试次数) 3. 代码示例(Python): 复制代码 隐藏代码
import time
from collections import deque
classAdaptiveSlidingWindow:
def__init__(self, max_requests=5, time_window=60):
self.max_requests = max_requests
self.time_window = time_window
self.requests = deque()
self.wait_time = 1
self.retry_count = 0
defcan_make_request(self):
now = time.time()
# 清除过期的请求记录
whileself.requests and now - self.requests[0] > self.time_window:
self.requests.popleft()
# 如果请求队列未满,可以发送请求
iflen(self.requests) < self.max_requests:
returnTrue
returnFalse
defrecord_request(self):
self.requests.append(time.time())
defhandle_429(self, retry_after=None):
self.retry_count += 1
if retry_after:
self.wait_time = int(retry_after)
else:
# 指数退避
self.wait_time = min(60, 2 ** self.retry_count)
time.sleep(self.wait_time)4. 优化策略: • 实现多级窗口控制(全局窗口和单域名窗口) • 根据不同网站特性调整初始参数 • 添加随机抖动(jitter)避免同步请求 • 实现请求优先级队列 5. 最佳实践: • 遵守robots.txt规则 • 设置合理的User-Agent • 实现请求失败重试机制 • 记录日志用于分析和调优 HTTP 的 X-Pingback 头在爬虫中有何意义?X-Pingback 头在爬虫中有几个重要意义:1) 帮助爬虫发现网站的 Pingback 端点,了解网站如何处理引用通知;2) 让爬虫能够尊重网站的引用政策,如果网站使用 Pingback,爬虫可以判断是否需要触发通知;3) 帮助爬虫避免不必要的请求,特别是当只是临时访问页面而不打算长期引用时;4) 有助于分析网站之间的引用关系和网络结构;5) 帮助爬虫识别网站使用的内容管理系统(如 WordPress 等);6) 使爬虫能够更好地遵守 robots.txt 中与 Pingback 相关的规则;7) 促进爬虫尊重网站的版权和引用规范。了解并尊重 X-Pingback 机制是负责任爬虫行为的重要部分。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的分布式滑动窗口?处理 HTTP 429 Too Many Requests 的分布式滑动窗口可以采用以下方法: 1. 基于 Redis 的滑动窗口实现: • 使用 Redis 的 ZSET 数据结构存储请求时间戳 • 每个请求到来时,将当前时间戳加入 ZSET,并移除窗口外的旧请求 • 检查 ZSET 长度是否超过限制,超过则触发限流 • 利用 Redis 的原子操作确保分布式环境下的线程安全 2. 分布式限流策略: • 实现中心化限流器:所有节点共享同一个限流窗口 • 或实现分散式限流:每个节点维护自己的限流窗口,但共享限流配置 3. 处理 429 响应: • 解析 Retry-After 头,确定延迟时间 • 实现指数退避算法,逐步增加重试间隔 • 记录错误信息,用于后续优化限流策略 4. 优化措施: • 使用连接池减少连接开销 • 实现请求优先级队列 • 添加监控指标,跟踪限流触发频率 • 根据目标网站特性动态调整限流参数 5. 代码示例(Redis实现): 复制代码 隐藏代码
def is_allowed(request_key, window_size, max_requests):
current_time = time.time()
pipe = redis.pipeline()
pipe.zadd(request_key, {str(current_time): current_time})
pipe.zremrangebyscore(request_key, 0, current_time - window_size)
pipe.zcard(request_key)
pipe.expire(request_key, window_size)
_, _, count, _ = pipe.execute()
return count <= max_requestsHTTP 的 X-Powered-By 头在爬虫中有何用途?X-Powered-By头在爬虫中有多种用途:1) 识别目标网站使用的技术栈,帮助爬虫确定适当的爬取策略;2) 绕过反爬机制,通过了解技术特征模拟真实浏览器请求;3) 进行网站指纹识别,在安全研究中寻找潜在漏洞;4) 进行竞争对手分析,了解行业技术趋势;5) 辅助自动化测试,根据不同技术调整测试策略。不过,出于安全考虑,许多现代网站已禁用此头字段以避免技术信息泄露。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的分布式固定窗口?处理HTTP 429 Too Many Requests的分布式固定窗口算法需要以下关键步骤: 1. 使用Redis作为共享存储:Redis的原子操作和过期特性非常适合实现分布式限流 2. 实现固定窗口算法: • 将时间划分为固定大小的窗口(如每秒、每分钟) • 为每个资源或API端点创建唯一的限流键 • 使用Redis的INCR命令和EXPIRE命令实现窗口计数器 3. 伪代码实现: 复制代码 隐藏代码
class DistributedFixedWindowRateLimiter:
def__init__(self, redis_client, window_size, max_requests):
self.redis = redis_client
self.window_size = window_size
self.max_requests = max_requests
defacquire(self, resource_key):
now = int(time.time())
window_start = (now // self.window_size) * self.window_size
current_window_key = f"rate_limit:{resource_key}:{window_start}"
current_count = self.redis.get(current_window_key)
current_count = int(current_count) if current_count else0
if current_count < self.max_requests:
self.redis.incr(current_window_key)
self.redis.expireat(current_window_key, window_start + self.window_size)
returnTrue
return False4. 处理429响应: • 检测429状态码 • 解析Retry-After头获取建议等待时间 • 实现退避算法避免立即重试 5. 分布式协调: • 确保所有爬虫节点使用相同的限流策略 • 考虑时间同步问题 • 实现Lua脚本保证原子性操作 6. 优化策略: • 为不同API端点设置差异化限流 • 实现动态调整机制 • 添加容错处理(如Redis不可用时的降级方案) 这种方法可以有效防止爬虫被网站封禁,同时提高爬虫的效率和稳定性。 HTTP 的 X-Request-ID 头在爬虫日志追踪中有何作用?HTTP 的 X-Request-ID 头在爬虫日志追踪中扮演着重要角色:1) 提供唯一标识符,用于追踪单个请求在系统中的完整生命周期;2) 帮助分布式系统中关联不同节点处理同一请求的日志;3) 便于错误排查和故障定位,通过ID快速找到相关日志记录;4) 支持请求去重,避免重复爬取;5) 有助于性能分析,评估爬虫处理特定请求的效率;6) 在负载均衡中保持会话一致性;7) 为安全审计提供可追踪的请求路径。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的分布式漏桶算法?处理429 Too Many Requests的分布式漏桶算法实现方案: 1. 系统架构设计: • 使用Redis作为中央存储系统记录请求状态 • 每个爬虫节点实现漏桶逻辑 • 建立监控机制检测429错误并动态调整 2. 核心实现步骤: a. 定义漏桶参数:桶容量、流出速率、时间窗口 b. 使用Redis实现分布式漏桶: 1. 检查漏桶状态 2. 桶未满时允许请求并更新状态 3. 桶已满时等待或丢弃请求 4. 收到429响应时记录并延长等待时间 d. 动态调整机制:根据响应时间和错误率自动调整 • 采用有序集合或计数器记录请求 • 每个请求记录时间戳和令牌数量 • 定期清理过期记录 c. 请求处理流程: 3. 代码实现要点: 复制代码 隐藏代码
class DistributedLeakyBucket:
def__init__(self, redis_host, capacity, rate):
self.redis = redis.StrictRedis(host=redis_host)
self.capacity = capacity # 桶容量
self.rate = rate # 每秒请求数
self.key = "leaky_bucket"
defallow_request(self):
# 使用Redis事务确保原子性
withself.redis.pipeline() as pipe:
whileTrue:
try:
pipe.watch(self.key)
current = int(pipe.get(self.key) or0)
if current >= self.capacity:
pipe.unwatch()
returnFalse
pipe.multi()
pipe.incr(self.key)
pipe.expire(self.key, 60)
pipe.execute()
returnTrue
except redis.WatchError:
continue4. 高级优化策略: • 多级漏桶:为不同优先级请求设置不同漏桶 • 自适应速率调整:根据响应时间动态调整 • 请求预热:开始时低速率,逐渐增加到目标 • 分布式协调:使用消息队列协调多节点 5. 监控与日志: • 记录请求速率、错误率、响应时间 • 设置异常情况告警 • 定期分析日志优化策略 通过以上方案,可以有效控制爬虫请求速率,避免触发429错误,同时提高爬取效率和稳定性。 HTTP 的 X-Robots-Tag 头在爬虫中有何意义?X-Robots-Tag 是一个 HTTP 响应头,用于向搜索引擎爬虫和其他网络爬虫提供指令,指导它们如何处理特定网页或资源。它的主要意义包括:1) 提供比 robots.txt 更精细的内容控制;2) 可以针对特定 URL、文件类型或资源设置不同指令;3) 能够控制非 HTML 资源(如图片、PDF)的索引行为;4) 支持多种指令如 noindex(禁止索引)、nofollow(禁止跟随链接)、noarchive(禁止缓存)等;5) 可在服务器级别设置,适用于无法修改 HTML 内容的情况;6) 提供跨网站应用的能力,特别是在 CDN 或反向代理环境中。这使得网站管理员能够更灵活地管理爬虫行为,优化内容展示和保护敏感信息。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的分布式随机重试?处理429 Too Many Requests的分布式随机重试策略包括以下几个关键点: 1. 解析Retry-After头:首先检查响应头中的Retry-After字段,如果有,则按照建议的时间等待;如果没有,使用默认退避策略。 2. 实现指数退避算法:采用指数退避策略,每次重试的等待时间 = 基础延迟 × (2^重试次数) + 随机抖动,避免多个节点同时重试。 3. 分布式协调:使用Redis或Zookeeper等分布式服务实现全局锁或延迟队列,确保不同节点的重试请求在时间上分散开。 4. 请求限流:实现全局请求速率限制,使用令牌桶或漏桶算法控制所有节点的总请求频率。 5. IP轮换:在分布式环境中使用代理IP池,结合随机重试策略分散请求压力。 6. 监控与自适应:监控429错误率,根据错误动态调整请求频率,实现自适应重试策略。 7. 唯一标识符:为每个请求生成唯一ID,在分布式系统中跟踪请求状态,避免重复处理。 8. 降级策略:当持续收到429错误时,临时降低爬取频率或切换到备用数据源。 HTTP 的 X-Runtime 头在爬虫性能分析中有何用途?X-Runtime头在爬虫性能分析中有多种用途:1) 监控目标服务器响应时间,及时发现性能异常;2) 根据响应时间动态调整爬取频率,避免给服务器过大压力;3) 评估服务器负载状况,优化爬取策略;4) 检测反爬机制,当响应时间异常时可能表示触发了反爬;5) 作为性能基准,测试不同爬取策略对目标网站的影响;6) 帮助爬虫决定请求优先级,优先爬取响应快的页面。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的分布式指数退避?处理HTTP 429 Too Many Requests的分布式指数退避策略如下: 1. 基本概念: • 429状态码表示请求频率过高 • 指数退避:每次重试前等待时间按指数增长(1s, 2s, 4s, 8s...) • 分布式协调:确保所有爬虫实例遵循一致的退避策略 2. 实现方案: • 中心化协调器:使用Redis等存储全局请求状态,所有爬虫实例共享退避时间 • 分布式锁:通过分布式锁机制协调各实例的退避行为 • 随机化退避:基础退避时间加上随机偏移量,避免同步恢复 3. 代码实现(Python示例): 复制代码 隐藏代码
import time
import random
import redis
classDistributedBackoff:
def__init__(self, redis_host='localhost'):
self.redis = redis.StrictRedis(host=redis_host)
self.base_backoff = 1
self.max_backoff = 300
self.jitter_factor = 0.1
defget_backoff_time(self, retry_count):
backoff = min(self.base_backoff * (2 ** retry_count), self.max_backoff)
jitter = backoff * self.jitter_factor * (2 * random.random() - 1)
returnmax(backoff + jitter, 1)
defhandle_429(self, retry_count):
backoff_time = self.get_backoff_time(retry_count)
# 使用Redis设置全局退避状态
key = f"backoff:{int(time.time() // 300)}"
self.redis.setex(key, int(backoff_time), "1")
time.sleep(backoff_time)
# 等待全局退避结束
whileself.redis.exists(key):
time.sleep(1)4. 优化策略: • 自适应退避:根据历史响应时间动态调整 • 分级退避:对不同类型请求应用不同策略 • 服务器特定策略:针对不同目标服务器定制参数 5. 最佳实践: • 设置最大退避时间上限(通常为5-10分钟) • 添加随机抖动(±10%)避免同步恢复 • 记录退避历史,分析优化策略 • 考虑使用成熟库如tenacity或backoff HTTP 的 X-UA-Compatible 头在爬虫中有何作用?X-UA-Compatible 头在爬虫中主要有以下几方面的作用:1) 控制渲染模式:帮助爬虫确定使用哪种浏览器引擎(如IE9模式、IE8模式等)来解析页面,确保内容被正确渲染;2) 模拟浏览器行为:使爬虫能够模拟特定版本的IE浏览器,获取与真实用户一致的内容;3) 处理兼容性问题:某些网站依赖特定渲染模式正确显示内容,设置此头可避免因渲染差异导致的内容获取不完整;4) 影响JavaScript执行:不同渲染模式对JS支持不同,此头会影响JS执行环境,进而影响动态内容的获取;5) 反爬虫检测:正确设置此头可以帮助爬虫伪装成正常浏览器,避免被网站识别为爬虫程序。 如何在爬虫中处理 HTTP 的 429 Too Many Requests 的分布式自适应重试?处理HTTP 429 Too Many Requests的分布式自适应重试策略包括以下几个方面: 1. 集中式限流管理:使用Redis等共享存储记录请求历史和限流状态,实现令牌桶或漏桶算法控制全局请求速率,避免所有实例同时突破限制。 2. 自适应重试策略: • 优先解析并使用服务器返回的Retry-After头部值 • 若无明确等待时间,采用指数退避算法:初始等待时间 = 基础延迟 × (2 ^ 重试次数) • 添加随机抖动(25%-75%)避免多个实例同步重试 • 设置最大等待时间上限(如300秒),避免无限等待 3. 分布式协调机制: • 实现分布式锁确保同一时间只有一个实例处理特定资源重试 • 使用消息队列管理重试任务,避免实例间竞争 • 实现背压机制,过载时自动减少并发请求数 4. 实现示例代码: 复制代码 隐藏代码
import time
import random
import redis
from requests.exceptions import HTTPError
classAdaptiveRetryHandler:
def__init__(self, redis_host='localhost', redis_port=6379):
self.redis = redis.StrictRedis(host=redis_host, port=redis_port)
self.base_delay = 1
self.max_delay = 300
defshould_retry(self, response, retry_count=0):
if response.status_code != 429:
returnFalse
retry_after = response.headers.get('Retry-After')
if retry_after:
try:
delay = int(retry_after)
except ValueError:
retry_date = parsedate(retry_after)
delay = max(0, (retry_date - datetime.now()).total_seconds())
else:
delay = min(self.base_delay * (2 ** retry_count), self.max_delay)
jitter = random.uniform(0.25, 0.75)
delay = delay * (1 + jitter)
retry_key = f"retry:{response.url}"
self.redis.setex(retry_key, int(delay), "1")
returnTrue, delay
defmake_request(self, request_func, *args, **kwargs):
retry_count = 0
whileTrue:
try:
response = request_func(*args, **kwargs)
response.raise_for_status()
return response
except HTTPError as e:
if e.response.status_code == 429:
should_retry, delay = self.should_retry(e.response, retry_count)
if should_retry:
print(f"Rate limited. Retrying after {delay:.2f} seconds...")
time.sleep(delay)
retry_count += 1
continue
raise5. 高级优化: • 实现请求优先级队列,优先处理高价值请求 • 根据不同目标网站定制不同的限流策略 • 实现IP/用户代理轮换,避免单一标识符被限流 • 监控限流频率,自动调整爬取策略 HTTP 的 X-XSS-Protection 头在爬虫中有何意义?在爬虫中,X-XSS-Protection 头具有以下意义:1) 作为网站安全状况的指标,帮助爬虫评估目标网站的安全实践;2) 帮助爬虫识别可能存在XSS漏洞的网站;3) 指导爬虫调整行为,如对启用了XSS保护的网站可能采取更谨慎的内容处理方式;4) 在安全审计爬虫中作为合规性检查点;5) 帮助区分测试环境与生产环境,因为测试环境常禁用此类安全头。需要注意的是,现代浏览器已逐渐弃用此头,转而采用CSP,但它在爬虫安全评估中仍有参考价值。


 rhdou注册了
rhdou注册了 netthing注册了
netthing注册了 暗虫皇注册了
暗虫皇注册了
 stalkerru注册了
stalkerru注册了
 abu注册了
abu注册了 nobestirn注册了
nobestirn注册了 ianf339注册了
ianf339注册了